Use TMA without CUDA
Introduction
TMA (Tensor Memory Accelerator) is essential to archive peak bandwidth on Hopper GPUs.
In the past I wrote a blogpost on how to use TMA in pure CUDA. It might help to read this blogpost to understand concepts more deeply.
Below I will explain how to leverage TMA using Mojo a new programming language for parallel computing.
Code Analysis
The code below is adapted from an example in the Mojo repo We will now analysis this code line by line.
# ===----------------------------------------------------------------------=== #
# Copyright (c) 2025, Modular Inc. All rights reserved.
#
# Licensed under the Apache License v2.0 with LLVM Exceptions:
# https://llvm.org/LICENSE.txt
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ===----------------------------------------------------------------------=== #
from builtin.io import _printf
from gpu import barrier
from gpu.host import DeviceContext
from gpu.host._compile import _get_gpu_target
from gpu.host._nvidia_cuda import TMADescriptor, create_tma_descriptor
from gpu.id import block_idx, thread_idx
from gpu.memory import (
_GPUAddressSpace,
cp_async_bulk_tensor_shared_cluster_global,
cp_async_bulk_tensor_global_shared_cta,
tma_store_fence,
)
from gpu.sync import (
mbarrier_arrive_expect_tx_shared,
mbarrier_init,
mbarrier_try_wait_parity_shared,
cp_async_bulk_commit_group,
cp_async_bulk_wait_group,
)
from memory import UnsafePointer, stack_allocation
from utils.index import Index
from utils.static_tuple import StaticTuple
alias GMEM_HEIGHT = 8
alias GMEM_WIDTH = 8
alias BLOCK_SIZE = 4
alias SMEM_HEIGHT = BLOCK_SIZE
alias SMEM_WIDTH = BLOCK_SIZE
@__llvm_arg_metadata(descriptor, `nvvm.grid_constant`)
fn kernel_copy_async_tma[block_size: Int](descriptor: TMADescriptor):
var shmem = stack_allocation[
block_size * block_size,
DType.float32,
alignment=1024,
address_space = _GPUAddressSpace.SHARED,
]()
var mbar = stack_allocation[
1, Int64, address_space = _GPUAddressSpace.SHARED
]()
var descriptor_ptr = UnsafePointer(to=descriptor).bitcast[NoneType]()
x = block_idx.x * block_size
y = block_idx.y * block_size
col = thread_idx.x % block_size
row = thread_idx.x // block_size
# LOAD
if thread_idx.x == 0:
mbarrier_init(mbar, 1)
mbarrier_arrive_expect_tx_shared(mbar, block_size * block_size * 4)
cp_async_bulk_tensor_shared_cluster_global(
shmem, descriptor_ptr, mbar, Index(x, y)
)
barrier()
mbarrier_try_wait_parity_shared(mbar, 0, 10000000)
# COMPUTE
shmem[row * block_size + col] += row * block_size + col
# FENCE
barrier()
tma_store_fence()
# STORE
if thread_idx.x == 0:
cp_async_bulk_tensor_global_shared_cta(
shmem, descriptor_ptr, Index(x, y)
)
cp_async_bulk_commit_group()
cp_async_bulk_wait_group[0]()
def test_tma_tile_copy(ctx: DeviceContext):
print("== test_tma_tile_copy")
var gmem_host = UnsafePointer[Float32].alloc(GMEM_HEIGHT * GMEM_WIDTH)
for i in range(GMEM_HEIGHT * GMEM_WIDTH):
gmem_host[i] = i
print("Initial matrices:")
for matrix_row in range(GMEM_HEIGHT // SMEM_HEIGHT):
for matrix_col in range(GMEM_WIDTH // SMEM_WIDTH):
print("\nMatrix at position (", matrix_row, ",", matrix_col, "):")
for row in range(SMEM_HEIGHT):
for col in range(SMEM_WIDTH):
idx = (matrix_row * SMEM_HEIGHT + row) * GMEM_WIDTH + (
matrix_col * SMEM_WIDTH + col
)
print(String(gmem_host[idx]).ljust(4), end=" ")
print()
print()
var gmem_dev = ctx.enqueue_create_buffer[DType.float32](
GMEM_HEIGHT * GMEM_WIDTH
)
ctx.enqueue_copy(gmem_dev, gmem_host)
var descriptor = create_tma_descriptor[DType.float32, 2](
gmem_dev,
(GMEM_HEIGHT, GMEM_WIDTH),
(GMEM_WIDTH, 1),
(SMEM_HEIGHT, SMEM_WIDTH),
)
ctx.enqueue_function[kernel_copy_async_tma[BLOCK_SIZE]](
descriptor,
grid_dim=(GMEM_HEIGHT // SMEM_HEIGHT, GMEM_WIDTH // SMEM_WIDTH, 1),
block_dim=(SMEM_HEIGHT * SMEM_WIDTH, 1, 1),
)
ctx.enqueue_copy(gmem_host, gmem_dev)
ctx.synchronize()
print("Final matrices:")
for matrix_row in range(GMEM_HEIGHT // SMEM_HEIGHT):
for matrix_col in range(GMEM_WIDTH // SMEM_WIDTH):
print("\nMatrix at position (", matrix_row, ",", matrix_col, "):")
for row in range(SMEM_HEIGHT):
for col in range(SMEM_WIDTH):
idx = (matrix_row * SMEM_HEIGHT + row) * GMEM_WIDTH + (
matrix_col * SMEM_WIDTH + col
)
print(String(gmem_host[idx]).ljust(4), end=" ")
print()
print()
gmem_host.free()
def main():
with DeviceContext() as ctx:
test_tma_tile_copy(ctx)
Host
Let us look first at the host code where we define the TMA descriptor:
# Initialize input matrix
var gmem_host = UnsafePointer[Float32].alloc(GMEM_HEIGHT * GMEM_WIDTH)
for i in range(GMEM_HEIGHT * GMEM_WIDTH):
gmem_host[i] = i
# Create device buffer and copy data
var gmem_dev = ctx.enqueue_create_buffer[DType.float32](
GMEM_HEIGHT * GMEM_WIDTH
)
ctx.enqueue_copy(gmem_dev, gmem_host)
# Create TMA descriptor
var descriptor = create_tma_descriptor[DType.float32, 2](
gmem_dev,
(GMEM_HEIGHT, GMEM_WIDTH),
(GMEM_WIDTH, 1),
(SMEM_HEIGHT, SMEM_WIDTH),
)
# Run kernel
ctx.enqueue_function[kernel_copy_async_tma[BLOCK_SIZE]](
descriptor,
grid_dim=(GMEM_HEIGHT // SMEM_HEIGHT, GMEM_WIDTH // SMEM_WIDTH, 1),
block_dim=(SMEM_HEIGHT * SMEM_WIDTH, 1, 1),
)
TMA needs the descriptor to see how the Layout of the tensor is defined. In the descriptor above we define the tensor we operate on to be GMEM_HEIGHT x GMEM_WIDTH matrix in row major format (i.e. with stride GMEM_WIDTH along the row dimension).
We furthermore define our shared memory layout to be SMEM_HEIGHT x SMEM_WIDTH. Note that using the CUDA API we would need to do something similar.
Kernel setup
Note the nvvm.grid_constant annotation which corresponds to the __grid_constant__ we need to give in CUDA.
@__llvm_arg_metadata(descriptor, `nvvm.grid_constant`)
fn kernel_copy_async_tma[block_size: Int](descriptor: TMADescriptor):
var shmem = stack_allocation[
block_size * block_size,
DType.float32,
alignment=1024,
address_space = _GPUAddressSpace.SHARED,
]()
var mbar = stack_allocation[
1, Int64, address_space = _GPUAddressSpace.SHARED
]()
var descriptor_ptr = UnsafePointer(to=descriptor).bitcast[NoneType]()
x = block_idx.x * block_size
y = block_idx.y * block_size
col = thread_idx.x % block_size
row = thread_idx.x // block_size
We'll than allocate shared memory, our memory bar, the pointer to the descriptor and the coordinates of the upper left tile of the SMEM_HEIGHT x SMEM_WIDTH memory we will later on copy to shared memory.
Visually that can be depicted as follows.
Our initial matrix looks like this:
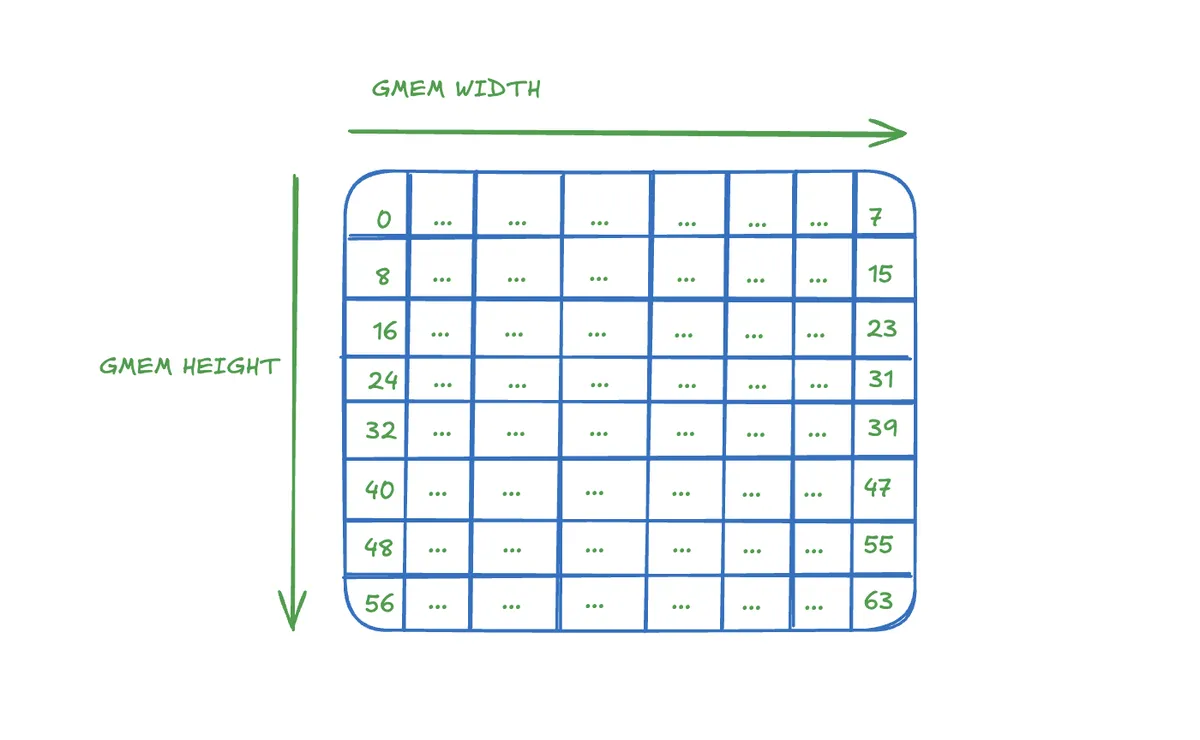
The descriptor defines in conjunction with the coordinated x and y how we tile the matrix. In our example that looks such:
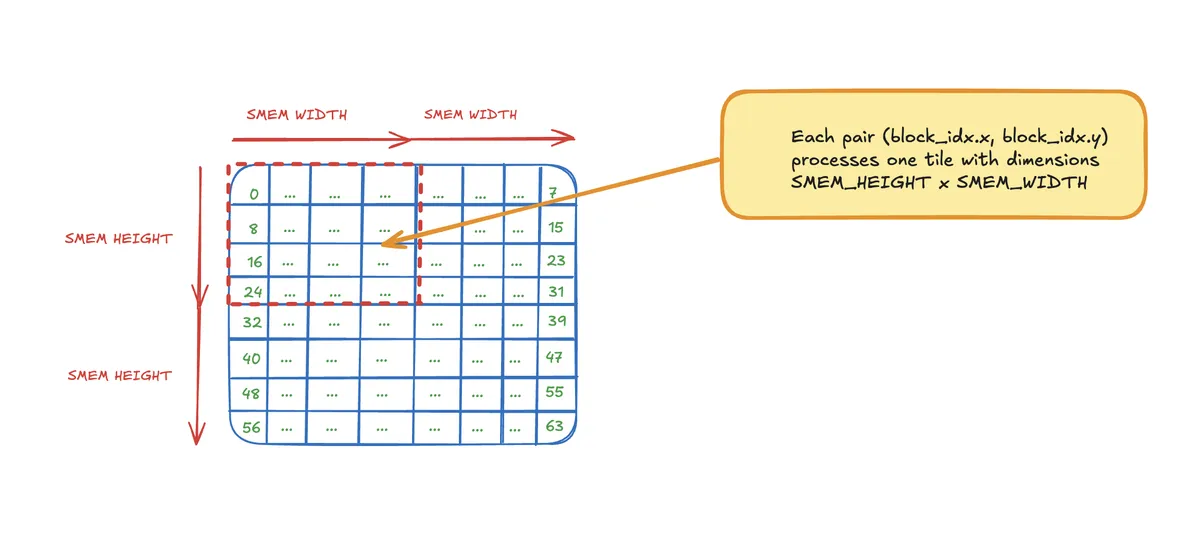
row and col than give us the information where into that tile of the matrix the current thread indexes into.
Copy operation
Next we copy the specified tile to shared memory
# LOAD
if thread_idx.x == 0:
mbarrier_init(mbar, 1)
mbarrier_arrive_expect_tx_shared(mbar, block_size * block_size * 4)
cp_async_bulk_tensor_shared_cluster_global(
shmem, descriptor_ptr, mbar, Index(x, y)
)
barrier()
mbarrier_try_wait_parity_shared(mbar, 0, 10000000)
Note that we do the copy only with one thread per block.
We initialise our barrier, give the information how many transactions to expect (note the factor 4 is because of the datatype here) and than perform the copy.
Afterwards we synchronise our threads and wait for the TMA load to be finished in mbarrier_try_wait_parity_shared.
I recommend to checkout tma.mojo and sync.mojo to understand how we can implement these kind of operations in Mojo using llvm intrinsics, for example mbarrier_init is implemented as follows:
@always_inline("nodebug")
fn mbarrier_init[
type: AnyType
](
shared_mem: UnsafePointer[
type, address_space = GPUAddressSpace.SHARED, **_
],
num_threads: Int32,
):
"""Initialize a shared memory barrier for synchronizing multiple threads.
Sets up a memory barrier in shared memory that will be used to synchronize
the specified number of threads. Only supported on NVIDIA GPUs.
Parameters:
type: The data type stored at the barrier location.
Args:
shared_mem: Pointer to shared memory location for the barrier.
num_threads: Number of threads that will synchronize on this barrier.
"""
@parameter
if is_nvidia_gpu():
llvm_intrinsic["llvm.nvvm.mbarrier.init.shared", NoneType](
shared_mem, num_threads
)
else:
constrained[
False, "The mbarrier_init function is not supported on AMD GPUs."
]()
For a documentation see the llvm and PTX docs.
Computation
After we copied our data to the shared memory we compute. Here I choose a simple example for clarity:
# COMPUTE
shmem[row * block_size + col] += row * block_size + col
# FENCE
barrier()
tma_store_fence()
This will simply add the index of the local coordinate in the current tile to the value that already is in shared memory.
For example before the kernel launch for down right subtile:
Matrix at position ( 1 , 1 ):
36.0 37.0 38.0 39.0
44.0 45.0 46.0 47.0
52.0 53.0 54.0 55.0
60.0 61.0 62.0 63.0
and after the kernel launch:
Matrix at position ( 1 , 1 ):
36.0 38.0 40.0 42.0
48.0 50.0 52.0 54.0
60.0 62.0 64.0 66.0
72.0 74.0 76.0 78.0
we see that this worked as expected.
Note that after computation we want to copy back using again the TMA unit.
Similar to mbarrier_try_wait_parity_shared we need a mechanism to know for sure TMA can begin to store because all computations are finished. We can do that using tma_store_fence.
Store
# STORE
if thread_idx.x == 0:
cp_async_bulk_tensor_global_shared_cta(
shmem, descriptor_ptr, Index(x, y)
)
cp_async_bulk_commit_group()
cp_async_bulk_wait_group[0]()
cp_async_bulk_commit_group is needed to commit the copy we performed on the line before.
cp_async_bulk_wait_group than waits until 0 TMA operations are pending.
Conclusion
I hope this blogpost serves as a gentle introduction on how to leverage the TMA unit in Hopper GPUs.
As mentioned above I recommend to checkout the code yourself to get a deeper understanding. Colfax wrote a helpful blog on TMA as well using CUTLASS and I wrote a blogpost using CUDA. The code I used in my experiments can be found on my Github.