SBO and LBO explained visually
SBO and LBO are essential to write correct Kernels on B200 GPUs that leverage Tensor Cores. That is because they need to be provided to the SMEM descriptor that the tcgen05 MMA op expects the programmer to provide as an operand. The corresponding section in the PTX docs commonly is perceived as confusing and in this blogpost I try to explain the mechanism for both K-Major and M-Major matrix operands.
Swizzle Atoms
To understand notation of swizzle in CUDA C++ we need to first familiarise ourselves with the notation of Swizzle Atoms. We can extract the following information from PTX docs:
| Swizzling Mode | Leading Dimension / Major-ness | Swizzle Atom Layout |
|---|---|---|
| 128B | M/N | 8×8 |
| 128B | K | 8×8 |
| 64B | M/N | 4×8 |
| 64B | K | 8×4 |
| 32B | M/N | 2×8 |
| 32B | K | 8×2 |
| None | M/N | 1×8 |
| None | K | 8×1 |
Note that this is for elements with 128 bits. If we consider the case of datatype T the table needs to be adjusted such that we "stretch" the atom across the non major mode by 128 / sizeof(T) across the major mode. For example for BFloat16 the table turns into:
| Swizzling Mode | Leading Dimension / Major-ness | Adjusted Swizzle Atom Layout (BF16) |
|---|---|---|
| 128B | M/N | 64×8 |
| 128B | K | 8×64 |
| 64B | M/N | 32×8 |
| 64B | K | 8×32 |
| 32B | M/N | 16×8 |
| 32B | K | 8×16 |
| None | M/N | 8×8 |
| None | K | 8×8 |
alternatively we could write:
| Swizzling Mode | Leading Dimension / Major-ness | Adjusted Swizzle Atom Layout |
|---|---|---|
| 128B | M/N | 128B × 8 |
| 128B | K | 8 × 128B |
| 64B | M/N | 64B × 8 |
| 64B | K | 8 × 64B |
| 32B | M/N | 32B × 8 |
| 32B | K | 8 × 32B |
| None | M/N | 16B × 8 |
| None | K | 8 × 16B |
Cover a Tile with Swizzle Atoms
The covering of a tile with Swizzle Atoms works as follows for K-Major and M-Major.
For K-Major we have a Covering as follows. Each number indiciates the order in which we lay out the swizzle atoms. (here right direction is K-Mode, down direction is M-Mode). Note that if we increased one of the two Modes the picture below would of course extend naturally. For visualisation i choose a tile of smaller size here. Although I use 128B Swizzle here, the process of covering is the same for other Swizzle Atoms aswell.
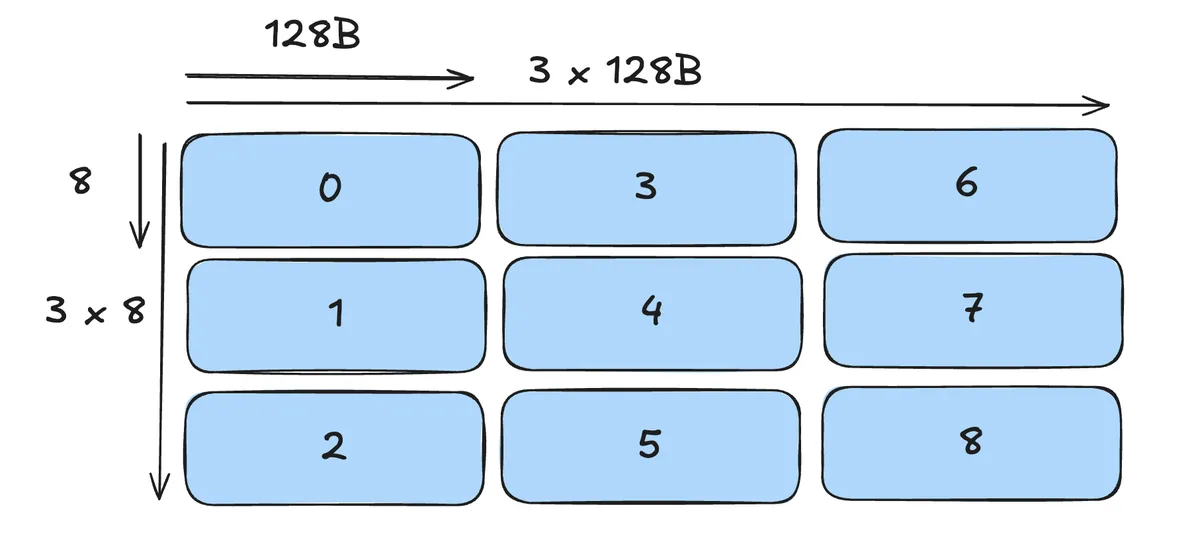
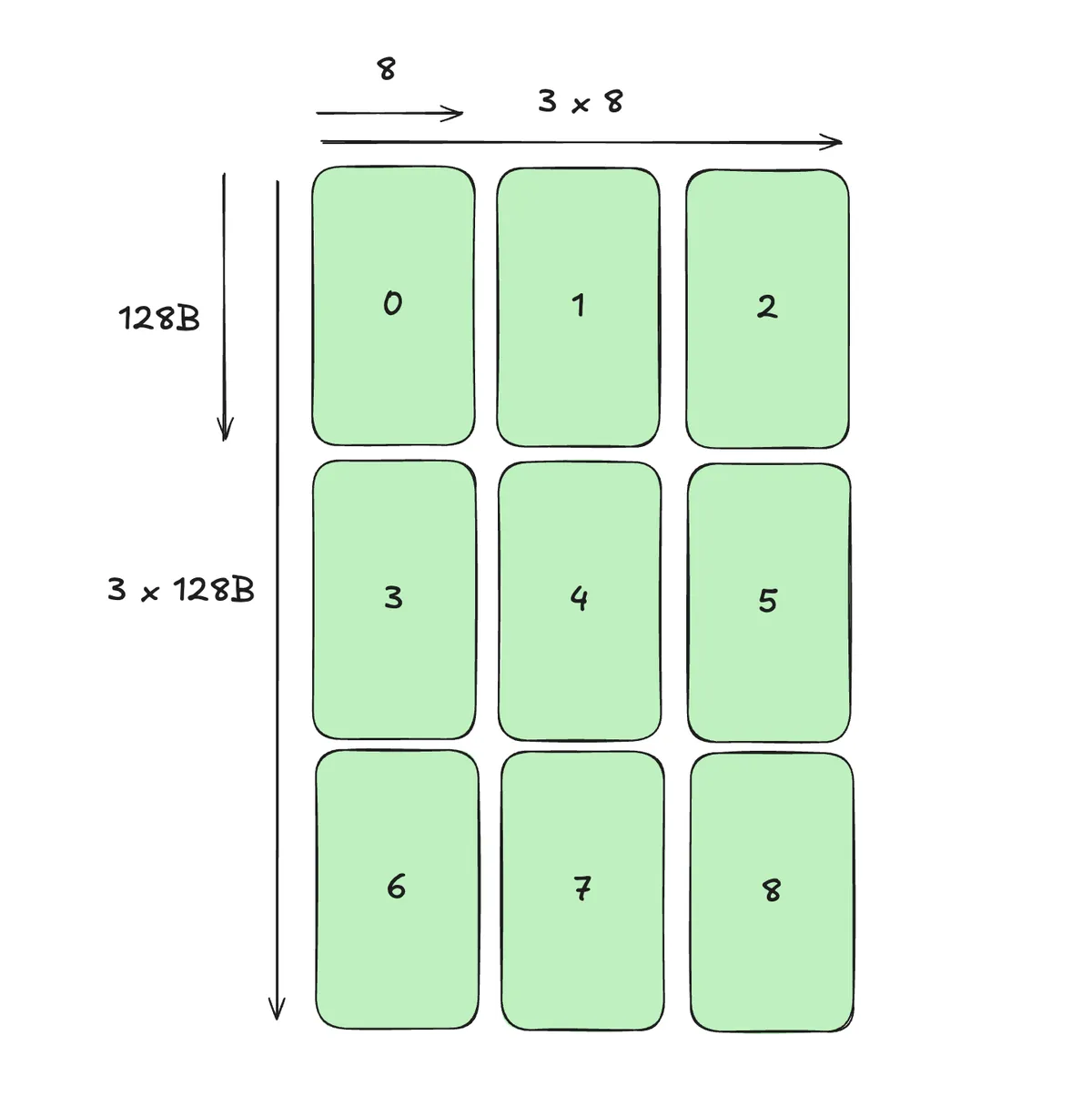
For M-Major we have the following picture:
Determine SBO and LBO
Let us first pull the definition of LBO and SBO from the PTX docs:
LBO:
| Major-ness | Case | Definition |
|---|---|---|
| K-Major | No-Swizzling | Offset from one row to the second column in the 128-bit element type matrix |
| K-Major | Swizzled layouts | Not used (treated as 1) |
| MN-Major | Interleave | Offset from the first to the next 8 columns |
| MN-Major | Swizzled layouts | Offset = (swizzle-byte-size / 16) rows |
SBO:
| Major-ness | Case | Definition |
|---|---|---|
| K-Major | — | Offset from the first 8 rows to the next 8 rows |
| MN-Major | Interleave | Offset from the first row to the next row |
| MN-Major | Swizzled layout | Offset from the first 8 columns to the next 8 columns |
K-Major
For K-Major that means the following visually for SBO and LBO in the no swizzle case:
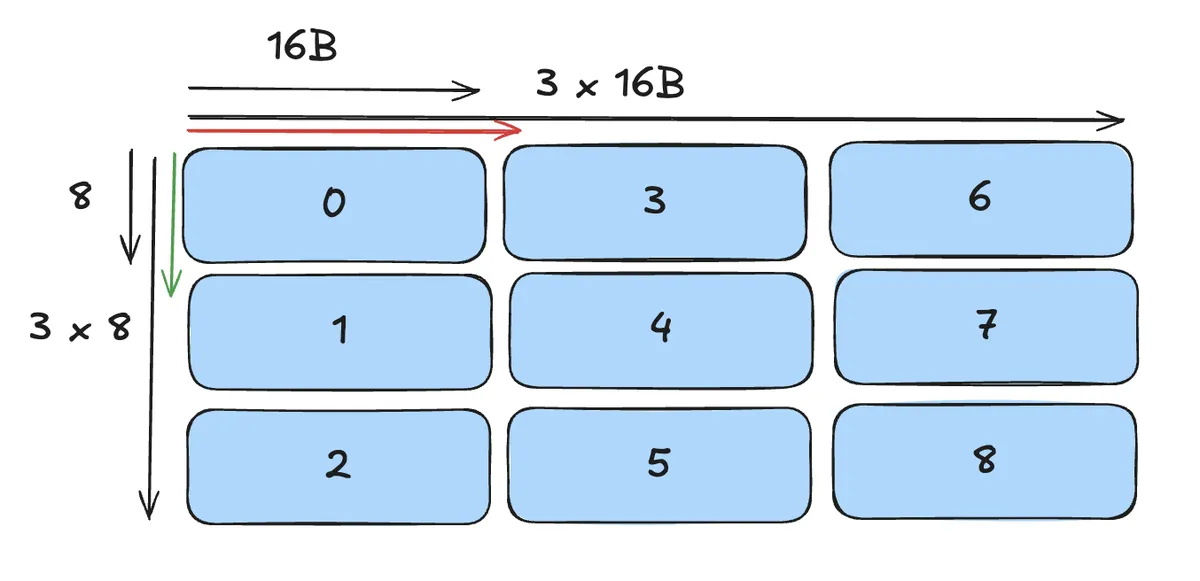
Here the red arrow indicates the LBO and the green arrow indicates the SBO. We can translate this into
- LBO = Jump one Atom into the direction of the major mode
- SBO = Jump one Atom into the direction of the minor mode
In code for BFloat16 (for other datatypes rescale the swizzle atoms accordingly):
constexpr uint32_t SWIZZLE_HEIGHT_M = BLOCK_M;
constexpr uint32_t SWIZZLE_WIDTH_M = 16U / sizeof(nv_bfloat16);
constexpr uint32_t SBO_M = 8U * (128U / 8U);
constexpr uint32_t LBO_M = (SWIZZLE_HEIGHT_M / 8U) * SBO_M;
constexpr uint32_t SWIZZLE_HEIGHT_N = BLOCK_N;
constexpr uint32_t SWIZZLE_WIDTH_N = 16U / sizeof(nv_bfloat16);
constexpr uint32_t SBO_N = 8U * (128U / 8U);
constexpr uint32_t LBO_N = (SWIZZLE_HEIGHT_N / 8U) * SBO_N;
For a 128B Swizzle we only have to determine SBO and it's definition (and thus visual interpretation) stays the same:
constexpr uint32_t SWIZZLE_HEIGHT_M = BLOCK_M;
constexpr uint32_t SWIZZLE_WIDTH_M = 128U / sizeof(nv_bfloat16);
constexpr uint32_t SWIZZLE_HEIGHT_N = BLOCK_N;
constexpr uint32_t SWIZZLE_WIDTH_N = 128U / sizeof(nv_bfloat16);
constexpr uint32_t SBO = 8U * (1024U / 8U);
Note that we can initialise the corresponding Tensormaps as:
//// Tensormap (No Swizzle)
inline void init_tensormap(CUtensorMap *tmap, const nv_bfloat16 *ptr,
uint64_t gmem_height, uint64_t gmem_width,
uint32_t smem_height, uint32_t smem_width) {
constexpr uint32_t rank = 2;
uint64_t globalDim[rank] = {gmem_width, gmem_height};
uint64_t globalStrides[rank - 1] = {gmem_width * sizeof(nv_bfloat16)};
uint32_t boxDim[rank] = {smem_width, smem_height};
uint32_t elementStrides[rank] = {1, 1};
CUresult err = cuTensorMapEncodeTiled(
tmap, CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_BFLOAT16, rank,
(void *)ptr, globalDim, globalStrides, boxDim, elementStrides,
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE,
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(err == CUDA_SUCCESS);
}
...
CUtensorMap tmap_a{}, tmap_b{};
init_tensormap(&tmap_a, static_cast<const nv_bfloat16 *>(a.data_ptr()), M, K,
SWIZZLE_HEIGHT_M, SWIZZLE_WIDTH_M);
init_tensormap(&tmap_b, static_cast<const nv_bfloat16 *>(b.data_ptr()), N, K,
SWIZZLE_HEIGHT_N, SWIZZLE_WIDTH_N);
//// Tensormap (Swizzle 128B)
inline void init_tensormap(CUtensorMap *tmap, const nv_bfloat16 *ptr,
uint64_t gmem_height, uint64_t gmem_width,
uint32_t smem_height, uint32_t smem_width) {
constexpr uint32_t rank = 2;
uint64_t globalDim[rank] = {gmem_width, gmem_height};
uint64_t globalStrides[rank - 1] = {gmem_width * sizeof(nv_bfloat16)};
uint32_t boxDim[rank] = {smem_width, smem_height};
uint32_t elementStrides[rank] = {1, 1};
CUresult err = cuTensorMapEncodeTiled(
tmap, CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_BFLOAT16, rank,
(void *)ptr, globalDim, globalStrides, boxDim, elementStrides,
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_128B,
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(err == CUDA_SUCCESS);
}
...
CUtensorMap tmap_a{}, tmap_b{};
init_tensormap(&tmap_a, static_cast<const nv_bfloat16 *>(a.data_ptr()), M, K,
SWIZZLE_HEIGHT_M, SWIZZLE_WIDTH_M);
init_tensormap(&tmap_b, static_cast<const nv_bfloat16 *>(b.data_ptr()), N, K,
SWIZZLE_HEIGHT_N, SWIZZLE_WIDTH_N);
Note that in this case we need to transfer multiple times via 2d TMA copy as described in excellent blogpost of my friend Thien.
If we'd like to avoid the loop we can leverage 3D TMA operation, for example like this:
//// Tensormap 3D swizzle
inline void init_tensormap_3d(CUtensorMap *tmap, const nv_bfloat16 *ptr,
uint64_t gmem_height, uint64_t gmem_width,
uint32_t smem_height, uint32_t plane_width) {
constexpr uint32_t rank = 3;
TVM_FFI_CHECK(gmem_width % plane_width == 0, ValueError)
<< "K dimension must be divisible by the 3D TMA plane width";
TVM_FFI_CHECK(BLOCK_K % plane_width == 0, ValueError)
<< "BLOCK_K must be divisible by the 3D TMA plane width";
uint32_t const smem_planes = BLOCK_K / plane_width;
// Interpret the source as [64, height, K/64]. With 128B swizzle, a single
// 3D TMA lands directly in the canonical K-major swizzled shared layout.
uint64_t globalDim[rank] = {plane_width, gmem_height,
gmem_width / plane_width};
uint64_t globalStrides[rank - 1] = {gmem_width * sizeof(nv_bfloat16),
plane_width * sizeof(nv_bfloat16)};
uint32_t boxDim[rank] = {plane_width, smem_height, smem_planes};
uint32_t elementStrides[rank] = {1, 1, 1};
CUresult err = cuTensorMapEncodeTiled(
tmap, CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_BFLOAT16, rank,
(void *)ptr, globalDim, globalStrides, boxDim, elementStrides,
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_128B,
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(err == CUDA_SUCCESS);
}
...
CUtensorMap tmap_a{}, tmap_b{};
init_tensormap_3d(&tmap_a, static_cast<const nv_bfloat16 *>(a.data_ptr()), M,
K, SWIZZLE_HEIGHT_M, SWIZZLE_WIDTH_M);
init_tensormap_3d(&tmap_b, static_cast<const nv_bfloat16 *>(b.data_ptr()), N,
K, SWIZZLE_HEIGHT_N, SWIZZLE_WIDTH_N);
Note that this can be visually interpreted such that we stack the above planes in a 3D cube:
M-Major
For M-Major the situation can be little bit more confusing because LBO and SBO mean visually different things for Swizzle vs no Swizzle case.
No Swizzle:
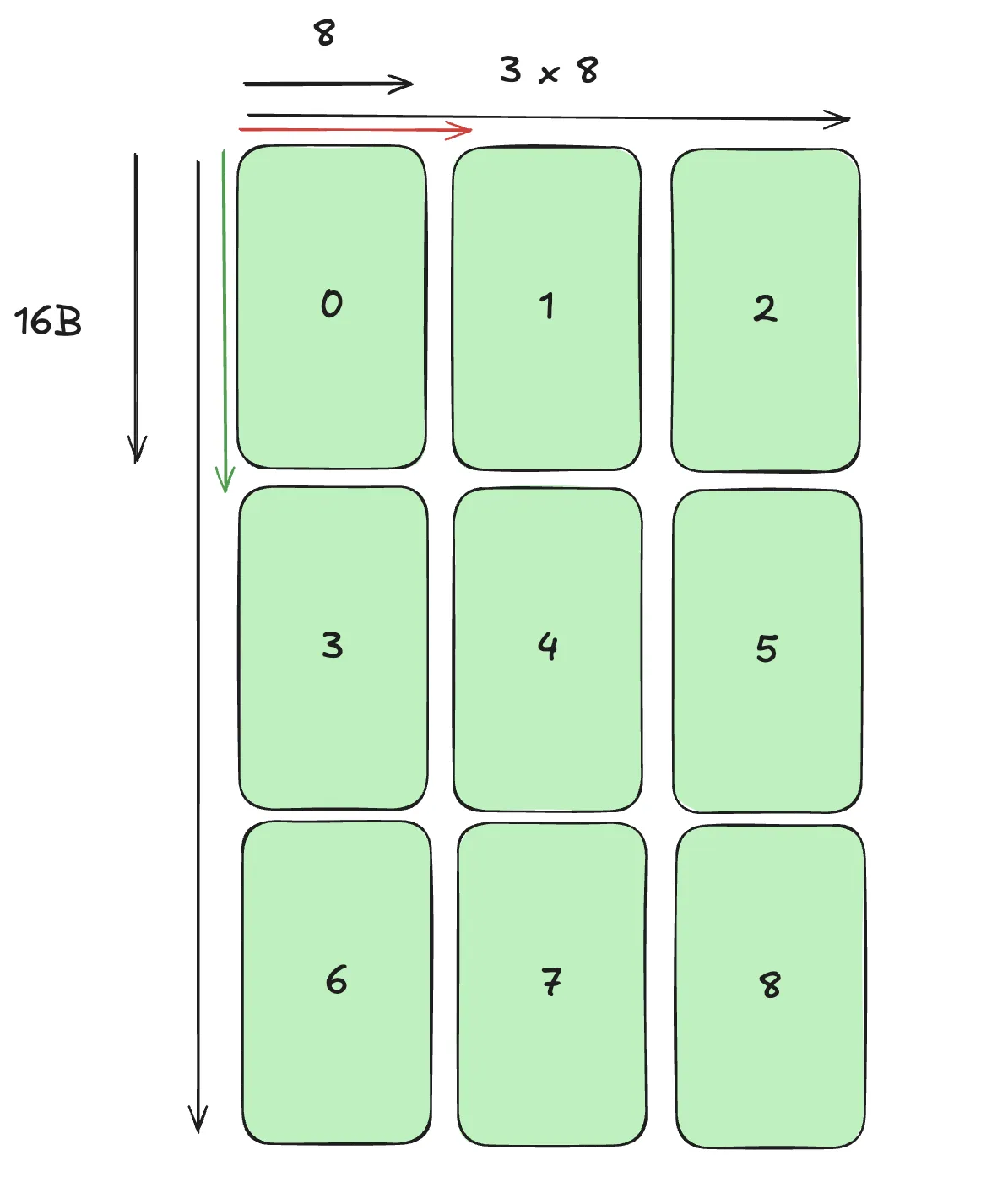
We can translate this into:
- LBO = Jump one Atom into the direction of the major mode
- SBO = Jump one Atom into the direction of the minor mode
i.e.
constexpr uint32_t SWIZZLE_HEIGHT_M = BLOCK_K;
constexpr uint32_t SWIZZLE_WIDTH_M = 16U / sizeof(nv_bfloat16);
constexpr uint32_t SWIZZLE_HEIGHT_N = BLOCK_K;
constexpr uint32_t SWIZZLE_WIDTH_N = 16U / sizeof(nv_bfloat16);
constexpr uint32_t LBO_M =
SWIZZLE_WIDTH_M * 8U * sizeof(nv_bfloat16);
constexpr uint32_t SBO_M = (SWIZZLE_HEIGHT_M / 8U) * LBO_M;
constexpr uint32_t LBO_N =
SWIZZLE_WIDTH_N * 8U * sizeof(nv_bfloat16);
constexpr uint32_t SBO_N = (SWIZZLE_HEIGHT_N / 8U) * LBO_N;
//// Tensormap
inline void init_tensormap(CUtensorMap *tmap, const nv_bfloat16 *ptr,
uint64_t gmem_height, uint64_t gmem_width,
uint32_t smem_height, uint32_t smem_width) {
constexpr uint32_t rank = 2;
uint64_t globalDim[rank] = {gmem_width, gmem_height};
uint64_t globalStrides[rank - 1] = {gmem_width * sizeof(nv_bfloat16)};
uint32_t boxDim[rank] = {smem_width, smem_height};
uint32_t elementStrides[rank] = {1, 1};
CUresult err = cuTensorMapEncodeTiled(
tmap, CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_BFLOAT16, rank,
(void *)ptr, globalDim, globalStrides, boxDim, elementStrides,
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE,
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(err == CUDA_SUCCESS);
}
...
CUtensorMap tmap_a{}, tmap_b{};
init_tensormap(&tmap_a, static_cast<const nv_bfloat16 *>(a.data_ptr()), K, M,
SWIZZLE_HEIGHT_M, SWIZZLE_WIDTH_M);
init_tensormap(&tmap_b, static_cast<const nv_bfloat16 *>(b.data_ptr()), K, N,
SWIZZLE_HEIGHT_N, SWIZZLE_WIDTH_N);
Equivalently in 3D:
//// Tensormap
inline void init_tensormap_3d(CUtensorMap *tmap, const nv_bfloat16 *ptr,
uint64_t gmem_height, uint64_t gmem_width,
uint32_t smem_height, uint32_t plane_width) {
constexpr uint32_t rank = 3;
TVM_FFI_CHECK(gmem_width % plane_width == 0, ValueError)
<< "K dimension must be divisible by the 3D TMA plane width";
TVM_FFI_CHECK(BLOCK_K % plane_width == 0, ValueError)
<< "BLOCK_K must be divisible by the 3D TMA plane width";
uint32_t const smem_planes = BLOCK_K / plane_width;
uint64_t globalDim[rank] = {plane_width, gmem_height, gmem_width / plane_width};
uint64_t globalStrides[rank - 1] = {
gmem_width * sizeof(nv_bfloat16), plane_width * sizeof(nv_bfloat16)};
uint32_t boxDim[rank] = {plane_width, smem_height, smem_planes};
uint32_t elementStrides[rank] = {1, 1, 1};
CUresult err = cuTensorMapEncodeTiled(
tmap, CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_BFLOAT16, rank,
(void *)ptr, globalDim, globalStrides, boxDim, elementStrides,
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE,
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(err == CUDA_SUCCESS);
}
...
CUtensorMap tmap_a{}, tmap_b{};
init_tensormap_3d(&tmap_a, static_cast<const nv_bfloat16 *>(a.data_ptr()), M,
K, SWIZZLE_HEIGHT_M, SWIZZLE_WIDTH_M);
init_tensormap_3d(&tmap_b, static_cast<const nv_bfloat16 *>(b.data_ptr()), N,
K, SWIZZLE_HEIGHT_N, SWIZZLE_WIDTH_N);
For Swizzle 128B the above table already hints that the two definitions are exact opposite. Compare:
- No Swizzle LBO: Offset from the first to the next 8 columns
- Swizzle LBO: Offset = (swizzle-byte-size / 16) rows
- No Swizzle SBO: Offset from the first row to the next row
- Swizzle SBO: Offset from the first 8 columns to the next 8 columns
So in our picture:
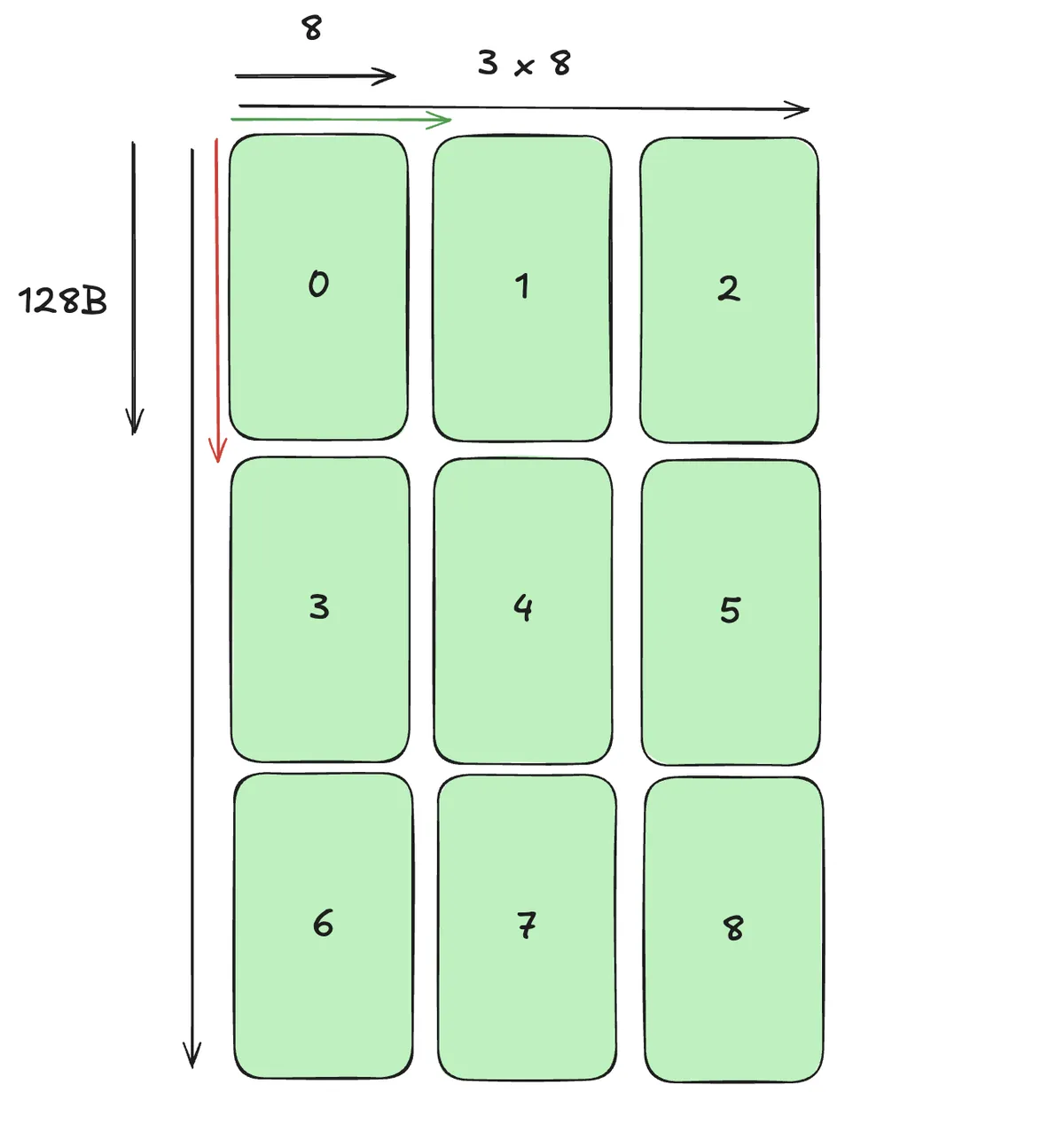
We can translate this into:
- LBO = Jump one Atom into the direction of the minor mode
- SBO = Jump one Atom into the direction of the major mode
In code:
//// Swizzle 128B -> stride-1 row slabs in MN-major order
constexpr uint32_t SWIZZLE_HEIGHT_M = BLOCK_K;
constexpr uint32_t SWIZZLE_WIDTH_M = 128U / sizeof(nv_bfloat16);
constexpr uint32_t SWIZZLE_HEIGHT_N = BLOCK_K;
constexpr uint32_t SWIZZLE_WIDTH_N = 128U / sizeof(nv_bfloat16);
constexpr uint32_t SBO_M =
SWIZZLE_WIDTH_M * 8U * sizeof(nv_bfloat16);
constexpr uint32_t LBO_M = (SWIZZLE_HEIGHT_M / 8U) * SBO_M;
constexpr uint32_t SBO_N =
SWIZZLE_WIDTH_N * 8U * sizeof(nv_bfloat16);
constexpr uint32_t LBO_N = (SWIZZLE_HEIGHT_N / 8U) * SBO_N;
//// Tensormap
inline void init_tensormap(CUtensorMap *tmap, const nv_bfloat16 *ptr,
uint64_t gmem_height, uint64_t gmem_width,
uint32_t smem_height, uint32_t smem_width) {
constexpr uint32_t rank = 2;
uint64_t globalDim[rank] = {gmem_width, gmem_height};
uint64_t globalStrides[rank - 1] = {gmem_width * sizeof(nv_bfloat16)};
uint32_t boxDim[rank] = {smem_width, smem_height};
uint32_t elementStrides[rank] = {1, 1};
CUresult err = cuTensorMapEncodeTiled(
tmap, CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_BFLOAT16, rank,
(void *)ptr, globalDim, globalStrides, boxDim, elementStrides,
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_128B,
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(err == CUDA_SUCCESS);
}
...
CUtensorMap tmap_a{}, tmap_b{};
init_tensormap(&tmap_a, static_cast<const nv_bfloat16 *>(a.data_ptr()), K, M,
SWIZZLE_HEIGHT_M, SWIZZLE_WIDTH_M);
init_tensormap(&tmap_b, static_cast<const nv_bfloat16 *>(b.data_ptr()), K, N,
SWIZZLE_HEIGHT_N, SWIZZLE_WIDTH_N);
We can of course equivalently treat the arrangement of 2D planes in 3D by stacking them into an equivalent cube to avoid the loop when scheduling TMA:
//// Tensormap
inline void init_tensormap_3d(CUtensorMap *tmap, const nv_bfloat16 *ptr,
uint64_t gmem_height, uint64_t gmem_width,
uint32_t smem_height, uint32_t smem_width) {
constexpr uint32_t rank = 3;
TVM_FFI_CHECK(gmem_width % SWIZZLE_WIDTH_M == 0, ValueError)
<< "tensor-map width must be divisible by the MN-major plane width";
TVM_FFI_CHECK(smem_width % SWIZZLE_WIDTH_M == 0, ValueError)
<< "shared-memory width must be divisible by the MN-major plane width";
uint32_t const smem_planes = smem_width / SWIZZLE_WIDTH_M;
uint64_t globalDim[rank] = {SWIZZLE_WIDTH_M, gmem_height,
gmem_width / SWIZZLE_WIDTH_M};
uint64_t globalStrides[rank - 1] = {
gmem_width * sizeof(nv_bfloat16),
SWIZZLE_WIDTH_M * sizeof(nv_bfloat16)};
uint32_t boxDim[rank] = {SWIZZLE_WIDTH_M, smem_height, smem_planes};
uint32_t elementStrides[rank] = {1, 1, 1};
CUresult err = cuTensorMapEncodeTiled(
tmap, CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_BFLOAT16, rank,
(void *)ptr, globalDim, globalStrides, boxDim, elementStrides,
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_128B,
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(err == CUDA_SUCCESS);
}
...
CUtensorMap tmap_a{}, tmap_b{};
init_tensormap_3d(&tmap_a, static_cast<const nv_bfloat16 *>(a.data_ptr()), K,
M, SWIZZLE_HEIGHT_M, BLOCK_M);
init_tensormap_3d(&tmap_b, static_cast<const nv_bfloat16 *>(b.data_ptr()), K,
N, SWIZZLE_HEIGHT_N, BLOCK_N);
Conclusion
I hope this blogpost made it easier how to calculate SBO and LBO for various configurations. Please see as a complement the blogpost I mentioned above or this excellent tutorial for how to use this knowledge to write performant Blackwell Kernels. If you want to program B200 GPUs I recommend Verda they have very good offers for GPUs and generously provided me with compute to perform the experiments.