Radix Top-K
Radix Top-K is an algorithm for finding the top-k elements in an array without sorting the full array.
For simplicity, assume the values are unsigned integers. The same idea can be extended to other representations.
Initial setup: Choose TOP_K and BITS_PER_ITER, and assume every element can be represented with NUM_BITS bits.
Then iteratively apply the following procedure:
- Extract the next
BITS_PER_ITERbits from all current candidates, starting from the most significant bits. - Count how many candidates fall into each bucket:
0, 1, ..., 2^{BITS_PER_ITER} - 1. - Perform an inclusive scan over the bucket counts.
- Let
K_remainingbeTOP_Kminus the number of elements already known to be in the top-k. Select the first bucket indexiwhereinclusive_scan[i] >= K_remaining. All elements in bucketsj < iare guaranteed to be in the top-k. Elements in bucketiremain candidates for the next round. Elements in bucketsj > iare discarded. - Repeat with the new candidates as input, updating
K_remainingby subtracting the number of elements already guaranteed to be in the top-k.
After all bit chunks have been processed, if more candidates remain than open top-k slots, keep only as many as needed. This can happen when multiple values are tied at the boundary.
As written, this finds the TOP_K smallest values. For TOP_K largest values, reverse the bucket order.
Simple description in an image:
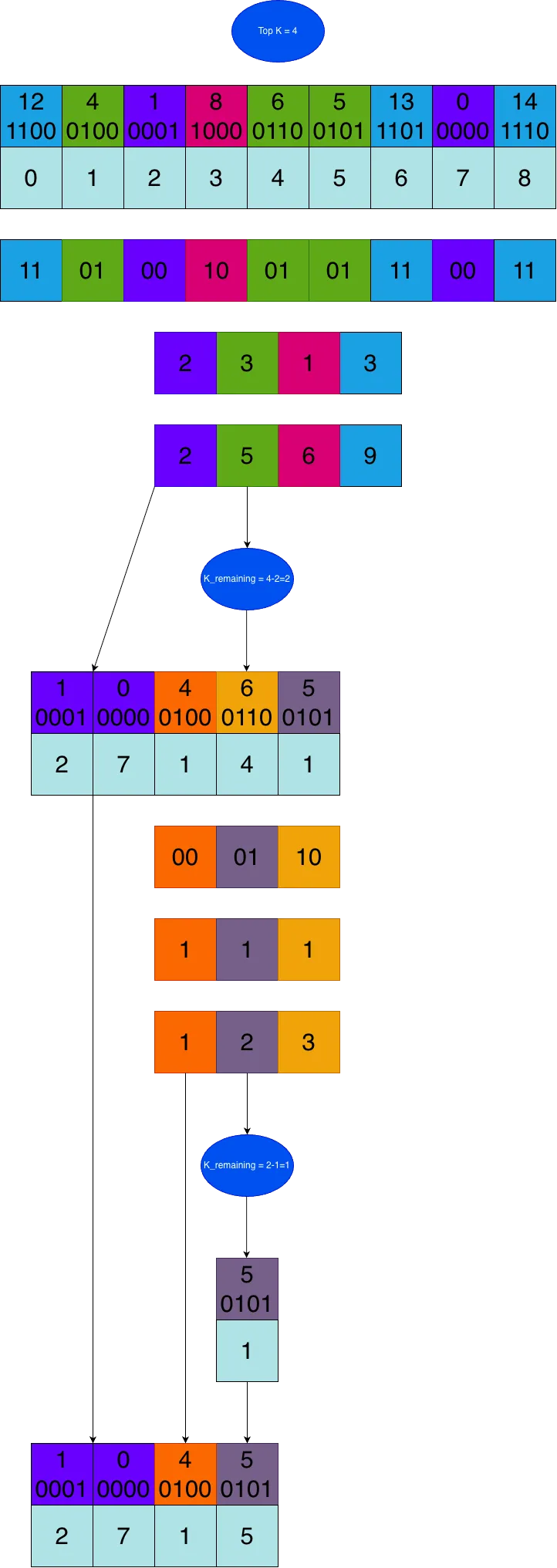
Minimal script to reproduce:
import torch
TOP_K = 4
NUM_BITS = 4
BITS_PER_ITER = 2
NUM_BUCKETS = 2**BITS_PER_ITER
def iteration(
iter_idx,
current_topk,
current_topk_idxs,
next_candidates,
next_candidate_idxs,
):
print(f"\nITER = {iter_idx}")
num_shift_right = NUM_BITS - (iter_idx + 1) * BITS_PER_ITER
shifted = torch.bitwise_right_shift(next_candidates, num_shift_right)
shifted = torch.bitwise_and(shifted, NUM_BUCKETS - 1)
print(f"{shifted=}")
hist = torch.bincount(shifted, minlength=NUM_BUCKETS)
print(f"{hist=}")
inclusive_scan = torch.cumsum(hist, dim=0)
print(f"{inclusive_scan=}")
num_needed = TOP_K - current_topk.numel()
mask = inclusive_scan >= num_needed
border = mask.float().argmax()
print(f"{border=}")
idxs_current_topk = shifted < border
idxs_next_candidates = shifted == border
current_topk = torch.cat([current_topk, next_candidates[idxs_current_topk]])
current_topk_idxs = torch.cat(
[current_topk_idxs, next_candidate_idxs[idxs_current_topk]]
)
next_candidates = next_candidates[idxs_next_candidates]
next_candidate_idxs = next_candidate_idxs[idxs_next_candidates]
print(f"{current_topk=}")
print(f"{current_topk_idxs=}")
print(f"{next_candidates=}")
print(f"{next_candidate_idxs=}")
return current_topk, current_topk_idxs, next_candidates, next_candidate_idxs
if __name__ == "__main__":
x = torch.tensor([12, 4, 1, 8, 6, 5, 13, 0, 14], device="cuda")
print(f"{x=}")
current_topk = torch.empty(0, dtype=x.dtype, device=x.device)
current_topk_idxs = torch.empty(0, dtype=torch.long, device=x.device)
next_candidates = x
next_candidate_idxs = torch.arange(x.numel(), device=x.device)
num_iters = NUM_BITS // BITS_PER_ITER
for iter_idx in range(num_iters):
(
current_topk,
current_topk_idxs,
next_candidates,
next_candidate_idxs,
) = iteration(
iter_idx,
current_topk,
current_topk_idxs,
next_candidates,
next_candidate_idxs,
)
num_remaining = TOP_K - current_topk.numel()
final_topk = torch.cat([current_topk, next_candidates[:num_remaining]])
final_topk_idxs = torch.cat(
[current_topk_idxs, next_candidate_idxs[:num_remaining]]
)
print(f"\n{final_topk=}")
print(f"{final_topk_idxs=}")
I hope this small note helps others to learn about Radix TopK Select.