Making matrix transpose really fast on Hopper GPUs
Introduction
In this blogpost I want to show how to implement highly efficent matrix transpose operation for Hopper GPUs. I will use native CUDA APIs without abstraction as I believe this is good way to learn about the hardware in detail. As you will see it is very important to use swizzling and being able to map swizzled indices to normal indices. Unfortunately this is not well documented in the otherwise excellent CUDA programming guide. I hope this blogpost gives more people ability to implement highly performant kernels for Hopper using native CUDA.
Swizzling
Visualizing swizzling pattern
Before implementing matrix transpose it is important we understand Swizzling.
Swizzling is a technique to avoid bank conflicts in shared memory.
In the following we will make use of concept that are essential for TMA on Hopper GPUs. If you are not familiar, please read my introductory blogpost on this topic.
To understand bank conflicts that can occur better let's visualize the bank assignment for a 2d int matrix.
We use the following layout without swizzling:
const int GMEM_WIDTH = 32;
const int GMEM_HEIGHT = 32;
const int BLOCK_SIZE = 32;
const int SMEM_WIDTH = BLOCK_SIZE;
const int SMEM_HEIGHT = BLOCK_SIZE;
// Create the tensor descriptor.
CUresult res = cuTensorMapEncodeTiled(
&tensor_map, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_INT32,
rank, // cuuint32_t tensorRank,
tensor_ptr, // void *globalAddress,
size, // const cuuint64_t *globalDim,
stride, // const cuuint64_t *globalStrides,
box_size, // const cuuint32_t *boxDim,
elem_stride, // const cuuint32_t *elementStrides,
// Interleave patterns can be used to accelerate loading of values that
// are less than 4 bytes long.
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
// Swizzling can be used to avoid shared memory bank conflicts.
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE,
// L2 Promotion can be used to widen the effect of a cache-policy to a
// wider set of L2 cache lines.
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
// Any element that is outside of bounds will be set to zero by the TMA
// transfer.
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
Than fill the shared memory tiles as follows.
smem_buffer[row * BLOCK_SIZE + col] = (row * BLOCK_SIZE + col) % 32;
We can visualize this:
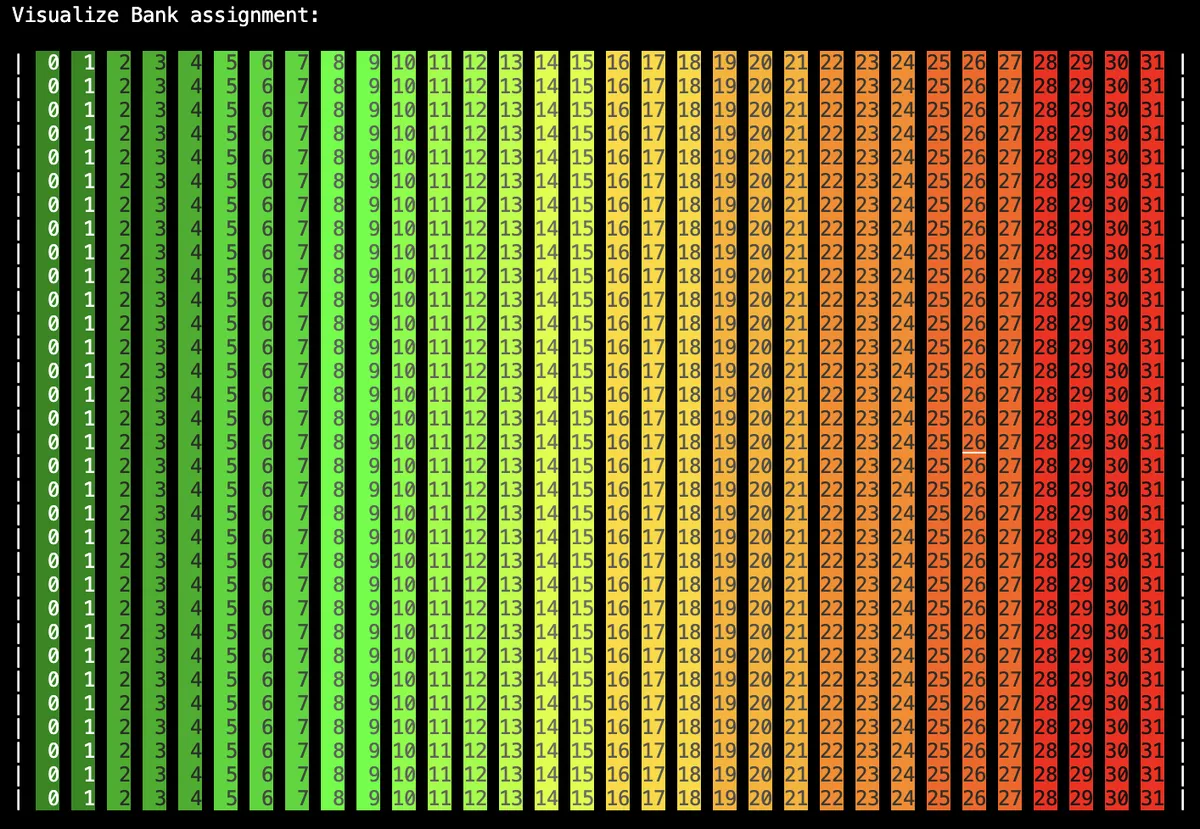
We see that each column gets assigned to one bank. That means if threads in the same warp access the the same column we will have a bank conflict. We can now modify the layout such that we use 128B swizzling pattern
// Create the tensor descriptor.
CUresult res = cuTensorMapEncodeTiled(
&tensor_map, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_INT32,
rank, // cuuint32_t tensorRank,
tensor_ptr, // void *globalAddress,
size, // const cuuint64_t *globalDim,
stride, // const cuuint64_t *globalStrides,
box_size, // const cuuint32_t *boxDim,
elem_stride, // const cuuint32_t *elementStrides,
// Interleave patterns can be used to accelerate loading of values that
// are less than 4 bytes long.
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
// Swizzling can be used to avoid shared memory bank conflicts.
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_128B,
// L2 Promotion can be used to widen the effect of a cache-policy to a
// wider set of L2 cache lines.
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
// Any element that is outside of bounds will be set to zero by the TMA
// transfer.
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(res == CUDA_SUCCESS);
Doing the same assignment for values in SMEM will now yield the following picture:
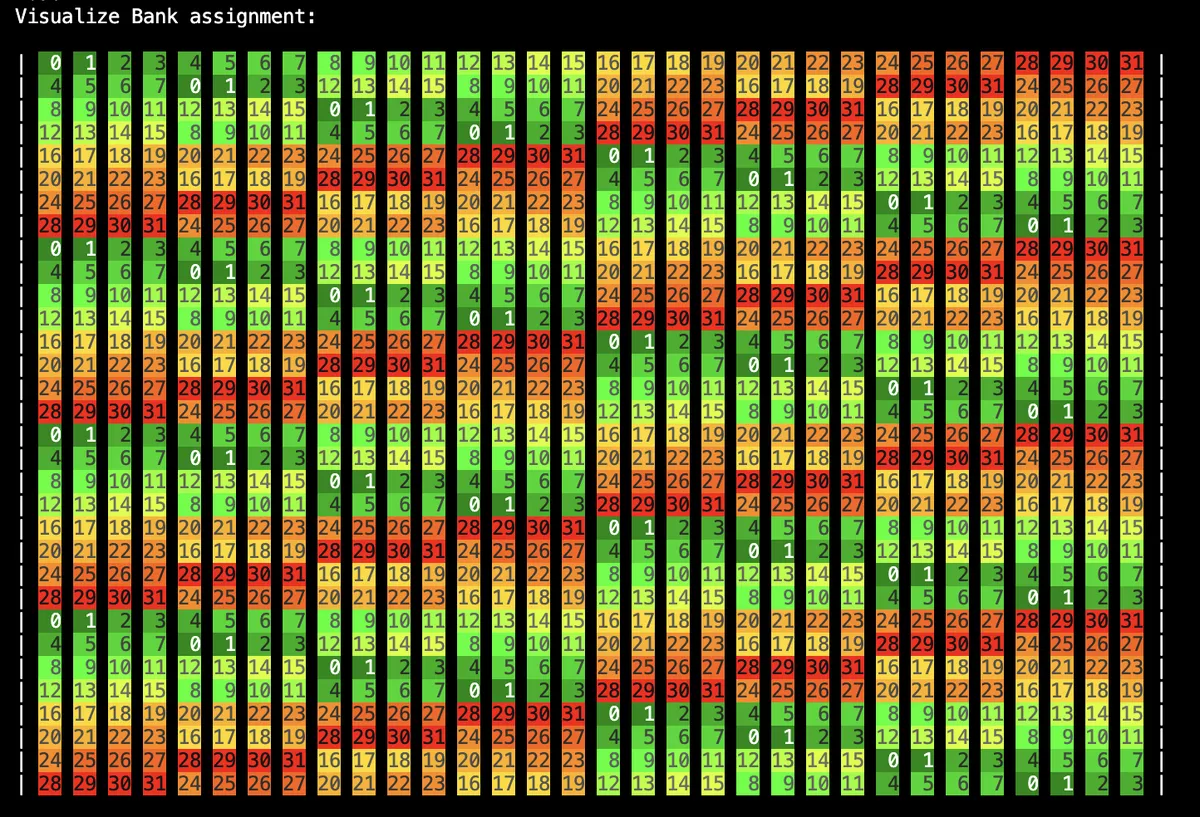
We can see that we have now significantly less potential bank conflicts.
The swizzling pattern is periodic and repeats after 8 * 32 * sizeof(int) = 128 entries in the matrix.
Modify shared memory with correct indices.
TMA does the swizzling for us when transferring data from GMEM to SMEM. But how can we recover the swizzling index?
It turns out there is a formula which is unfortunately not in the official NVIDIA docs for TMA swizzle.
The formula however can be found on a GCT Talk by Igor Terentyev.
The formula looks as follows:
 We can implement this for a a datatype which has
We can implement this for a a datatype which has sizeof(T)=4 as follows:
template <int BLOCK_SIZE>
__device__ int calculate_col_swizzle(int row, int col) {
int i16 = (row * BLOCK_SIZE + col) * 4 >> 4;
int y16 = i16 >> 3;
int x16 = i16 & 7;
int x16_swz = y16 ^ x16;
return ((x16_swz * 4) & (BLOCK_SIZE - 1)) + (col & 3);
}
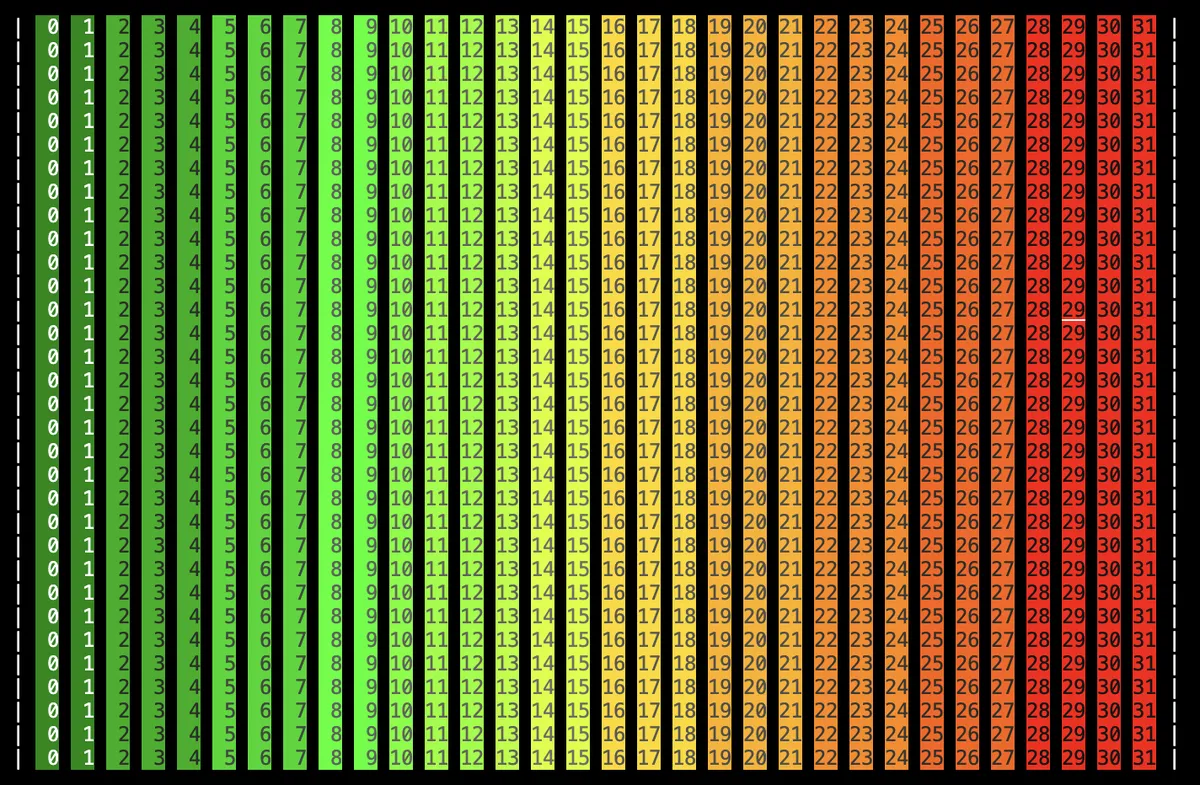
We can verify the correctness of this formula by
int col_swizzle = calculate_col_swizzle<BLOCK_SIZE>(row, col);
smem_buffer[row * BLOCK_SIZE + col_swizzle] = (row * BLOCK_SIZE + col) % 32;
with the swizzled layout.
Plotting yields than the unswizzled version:
Application: Matrix transpose
Naive approach
The following picture taken from an NVIDIA blogpost very clearly illustrates how to perform transposition in shared memory:
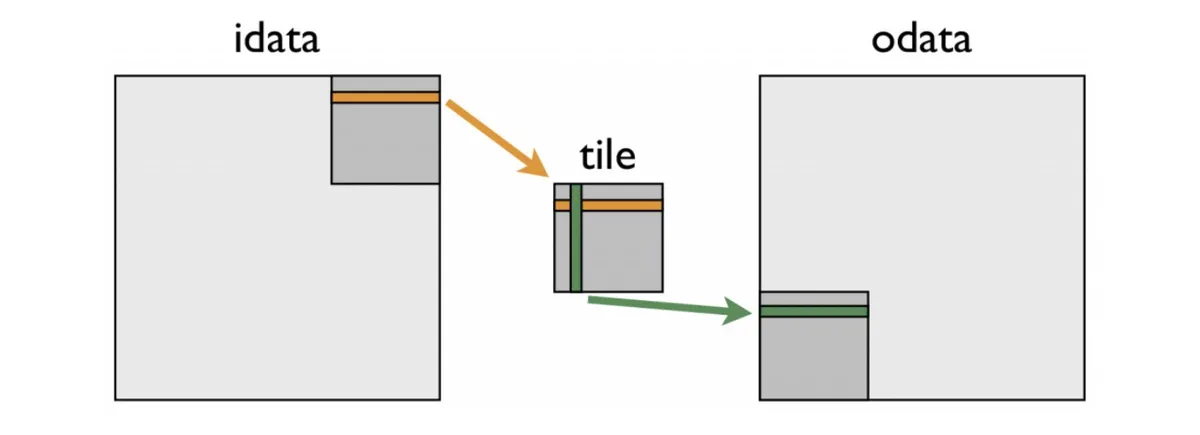
We take a matrix tile, transpose the tile and put at the other end of the matrix. Below we outline how we can implement a naive version without swizzling of this algorithm using TMA and Layouts. The full code can be found in my github repo which I will link at the end of this blogpost. We need two layouts, which are in relation of transpose:
// Create the tensor descriptor.
CUresult res = cuTensorMapEncodeTiled(
&tensor_map, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_FLOAT32,
rank, // cuuint32_t tensorRank,
tensor_ptr, // void *globalAddress,
size, // const cuuint64_t *globalDim,
stride, // const cuuint64_t *globalStrides,
box_size, // const cuuint32_t *boxDim,
elem_stride, // const cuuint32_t *elementStrides,
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE,
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(res == CUDA_SUCCESS);
CUresult res_tr = cuTensorMapEncodeTiled(
&tensor_map_tr, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_FLOAT32,
rank, // cuuint32_t tensorRank,
tensor_ptr_tr, // void *globalAddress,
size_tr, // const cuuint64_t *globalDim,
stride, // const cuuint64_t *globalStrides,
box_size_tr, // const cuuint32_t *boxDim,
elem_stride, // const cuuint32_t *elementStrides,
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE,
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(res_tr == CUDA_SUCCESS);
We can than use the following kernel to perform transposition
template <int BLOCK_SIZE>
__global__ void kernel(const __grid_constant__ CUtensorMap tensor_map,
const __grid_constant__ CUtensorMap tensor_map_tr) {
// The destination shared memory buffer of a bulk tensor operation should be
// 128 byte aligned.
__shared__ alignas(1024) float smem_buffer[BLOCK_SIZE * BLOCK_SIZE];
__shared__ alignas(1024) float smem_buffer_tr[BLOCK_SIZE * BLOCK_SIZE];
// Coordinates for upper left tile in GMEM.
int x = blockIdx.x * BLOCK_SIZE;
int y = blockIdx.y * BLOCK_SIZE;
int col = threadIdx.x % BLOCK_SIZE;
int row = threadIdx.x / BLOCK_SIZE;
// Initialize shared memory barrier with the number of threads participating in
// the barrier.
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier bar;
if (threadIdx.x == 0) {
// Initialize barrier. All `blockDim.x` threads in block participate.
init(&bar, blockDim.x);
// Make initialized barrier visible in async proxy.
cde::fence_proxy_async_shared_cta();
}
// Syncthreads so initialized barrier is visible to all threads.
__syncthreads();
barrier::arrival_token token;
if (threadIdx.x == 0) {
// Initiate bulk tensor copy.
cde::cp_async_bulk_tensor_2d_global_to_shared(&smem_buffer, &tensor_map, x,
y, bar);
// Arrive on the barrier and tell how many bytes are expected to come in.
token = cuda::device::barrier_arrive_tx(bar, 1, sizeof(smem_buffer));
} else {
// Other threads just arrive.
token = bar.arrive();
}
// Wait for the data to have arrived.
bar.wait(std::move(token));
// Transpose tile.
smem_buffer_tr[col * BLOCK_SIZE + row] = smem_buffer[row * BLOCK_SIZE + col];
// Wait for shared memory writes to be visible to TMA engine.
cde::fence_proxy_async_shared_cta();
__syncthreads();
// After syncthreads, writes by all threads are visible to TMA engine.
// Initiate TMA transfer to copy shared memory to global memory
if (threadIdx.x == 0) {
// Transpose tile inside matrix
cde::cp_async_bulk_tensor_2d_shared_to_global(&tensor_map_tr, y, x,
&smem_buffer_tr);
// Wait for TMA transfer to have finished reading shared memory.
// Create a "bulk async-group" out of the previous bulk copy operation.
cde::cp_async_bulk_commit_group();
// Wait for the group to have completed reading from shared memory.
cde::cp_async_bulk_wait_group_read<0>();
}
// Destroy barrier. This invalidates the memory region of the barrier. If
// further computations were to take place in the kernel, this allows the
// memory location of the shared memory barrier to be reused.
if (threadIdx.x == 0) {
(&bar)->~barrier();
}
}
Everything should be pretty straightforward. If you are not familiar with TMA please read my previous blogpost. For transpose we only need to
smem_buffer_tr[col * BLOCK_SIZE + row] = smem_buffer[row * BLOCK_SIZE + col];
once that is done we transfer the transposed tile to the opposite tile of the transposed layout (i.e. we swap x and y).
This kernel archieves the following performance for transpose of a matrix of dimension 32768 x 32768:
Latency = 9.81191 ms
Bandwidth = 875.46 GB/s
% of max = 26.5291 %
Swizzling transpose
In principle swizzling is pretty straightforward once we have the index formula above. Unfortunately this formula is hard to find so it took me some time to get it correct. For the layouts we only need to change the swizzling mode to
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_128B
The important thing is than, that we need to use the above formula to take into account that TMA swizzles and unswizzles the memory when transforming from GMEM->SMEM or from SMEM->GMEM.
The input layout is in row major format and the output layout is in column major layout so we need to use
col_swizzle instead of col for the shared memory corresponding to the input tile and row_swizzle instead of row for the output tile.
The full kernel looks as follows:
template <int BLOCK_SIZE>
__device__ int calculate_col_swizzle(int row, int col) {
int i16 = (row * BLOCK_SIZE + col) * 4 >> 4;
int y16 = i16 >> 3;
int x16 = i16 & 7;
int x16_swz = y16 ^ x16;
return ((x16_swz * 4) & (BLOCK_SIZE - 1)) + (col & 3);
}
template <int BLOCK_SIZE>
__device__ int calculate_row_swizzle(int row, int col) {
int i16_tr = (col * BLOCK_SIZE + row) * 4 >> 4;
int y16_tr = i16_tr >> 3;
int x16_tr = i16_tr & 7;
int x16_swz_tr = y16_tr ^ x16_tr;
return ((x16_swz_tr * 4) & (BLOCK_SIZE - 1)) + (row & 3);
}
template <int BLOCK_SIZE, int LOG_BLOCK>
__global__ void kernel(const __grid_constant__ CUtensorMap tensor_map,
const __grid_constant__ CUtensorMap tensor_map_tr) {
// The destination shared memory buffer of a bulk tensor operation should be
// 128 byte aligned.
__shared__ alignas(1024) float smem_buffer[BLOCK_SIZE * BLOCK_SIZE];
__shared__ alignas(1024) float smem_buffer_tr[BLOCK_SIZE * BLOCK_SIZE];
// Coordinates for upper left tile in GMEM.
int x = blockIdx.x * BLOCK_SIZE;
int y = blockIdx.y * BLOCK_SIZE;
int col = threadIdx.x & (BLOCK_SIZE - 1);
int row = threadIdx.x >> LOG_BLOCK;
int col_swizzle = calculate_col_swizzle<BLOCK_SIZE>(row, col);
int row_swizzle = calculate_row_swizzle<BLOCK_SIZE>(row, col);
// Initialize shared memory barrier with the number of threads participating in
// the barrier.
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier bar;
if (threadIdx.x == 0) {
// Initialize barrier. All `blockDim.x` threads in block participate.
init(&bar, blockDim.x);
// Make initialized barrier visible in async proxy.
cde::fence_proxy_async_shared_cta();
}
// Syncthreads so initialized barrier is visible to all threads.
__syncthreads();
barrier::arrival_token token;
if (threadIdx.x == 0) {
// Initiate bulk tensor copy.
cde::cp_async_bulk_tensor_2d_global_to_shared(&smem_buffer, &tensor_map, x,
y, bar);
// Arrive on the barrier and tell how many bytes are expected to come in.
token = cuda::device::barrier_arrive_tx(bar, 1, sizeof(smem_buffer));
} else {
// Other threads just arrive.
token = bar.arrive();
}
// Wait for the data to have arrived.
bar.wait(std::move(token));
// Transpose tile.
smem_buffer_tr[col * BLOCK_SIZE + row_swizzle] =
smem_buffer[row * BLOCK_SIZE + col_swizzle];
// Wait for shared memory writes to be visible to TMA engine.
cde::fence_proxy_async_shared_cta();
__syncthreads();
// After syncthreads, writes by all threads are visible to TMA engine.
// Initiate TMA transfer to copy shared memory to global memory
if (threadIdx.x == 0) {
// Transpose tile inside matrix
cde::cp_async_bulk_tensor_2d_shared_to_global(&tensor_map_tr, y, x,
&smem_buffer_tr);
// Wait for TMA transfer to have finished reading shared memory.
// Create a "bulk async-group" out of the previous bulk copy operation.
cde::cp_async_bulk_commit_group();
// Wait for the group to have completed reading from shared memory.
cde::cp_async_bulk_wait_group_read<0>();
}
// Destroy barrier. This invalidates the memory region of the barrier. If
// further computations were to take place in the kernel, this allows the
// memory location of the shared memory barrier to be reused.
if (threadIdx.x == 0) {
(&bar)->~barrier();
}
}
This kernel archieves the following performance for transpose of a matrix of dimension 32768 x 32768:
Latency = 6.86226 ms
Bandwidth = 1251.76 GB/s
% of max = 37.9323 %
Batches for threads
In memory bandwidth problems like matrix transpose it is common (as you can read in my blogpost on reduction or scan that we can get a huge performance boost by letting each thread handle multiple elements.
We can implement this as follows:
We launch only a proportion of the threads, i.e. instead of BLOCK_SIZE * BLOCK_SIZE threads we launch only BLOCK_SIZE * BLOCK_SIZE / BATCH_SIZE threads. We than let each thread handle BATCH_SIZE elements (note: in our implementation we chose BLOCK_SIZE=32 to launch maximum number of threads, we can increase BLOCK_SIZE=64 and launch with BATCH_SIZE=16 to again launch maximum number of threads.)
The full kernel looks as follows:
template <int BLOCK_SIZE>
__device__ int calculate_col_swizzle(int row, int col) {
int i16 = (row * BLOCK_SIZE + col) * 4 >> 4;
int y16 = i16 >> 3;
int x16 = i16 & 7;
int x16_swz = y16 ^ x16;
return ((x16_swz * 4) & (BLOCK_SIZE - 1)) + (col & 3);
}
template <int BLOCK_SIZE>
__device__ int calculate_row_swizzle(int row, int col) {
int i16_tr = (col * BLOCK_SIZE + row) * 4 >> 4;
int y16_tr = i16_tr >> 3;
int x16_tr = i16_tr & 7;
int x16_swz_tr = y16_tr ^ x16_tr;
return ((x16_swz_tr * 4) & (BLOCK_SIZE - 1)) + (row & 3);
}
template <int BLOCK_SIZE, int LOG_BLOCK, int BATCH_SIZE, int LOG_BATCH_SIZE>
__global__ void kernel(const __grid_constant__ CUtensorMap tensor_map,
const __grid_constant__ CUtensorMap tensor_map_tr) {
// The destination shared memory buffer of a bulk tensor operation should be
// 128 byte aligned.
__shared__ alignas(1024) float smem_buffer[BLOCK_SIZE * BLOCK_SIZE];
__shared__ alignas(1024) float smem_buffer_tr[BLOCK_SIZE * BLOCK_SIZE];
// Coordinates for upper left tile in GMEM.
int x = blockIdx.x * BLOCK_SIZE;
int y = blockIdx.y * BLOCK_SIZE;
int col = (threadIdx.x & (BLOCK_SIZE / BATCH_SIZE - 1)) * BATCH_SIZE;
int row = threadIdx.x >> (LOG_BLOCK - LOG_BATCH_SIZE);
// Initialize shared memory barrier with the number of threads participating in
// the barrier.
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier bar;
if (threadIdx.x == 0) {
// Initialize barrier. All `blockDim.x` threads in block participate.
init(&bar, blockDim.x);
// Make initialized barrier visible in async proxy.
cde::fence_proxy_async_shared_cta();
}
// Syncthreads so initialized barrier is visible to all threads.
__syncthreads();
barrier::arrival_token token;
if (threadIdx.x == 0) {
// Initiate bulk tensor copy.
cde::cp_async_bulk_tensor_2d_global_to_shared(&smem_buffer, &tensor_map, x,
y, bar);
// Arrive on the barrier and tell how many bytes are expected to come in.
token = cuda::device::barrier_arrive_tx(bar, 1, sizeof(smem_buffer));
} else {
// Other threads just arrive.
token = bar.arrive();
}
// Wait for the data to have arrived.
bar.wait(std::move(token));
// Transpose tile.
#pragma unroll
for (int j = 0; j < BATCH_SIZE; j++) {
int col_ = col + j;
int row_ = row;
int col_swizzle = calculate_col_swizzle<BLOCK_SIZE>(row_, col_);
int row_swizzle = calculate_row_swizzle<BLOCK_SIZE>(row_, col_);
smem_buffer_tr[col_ * BLOCK_SIZE + row_swizzle] =
smem_buffer[row_ * BLOCK_SIZE + col_swizzle];
}
// Wait for shared memory writes to be visible to TMA engine.
cde::fence_proxy_async_shared_cta();
__syncthreads();
// After syncthreads, writes by all threads are visible to TMA engine.
// Initiate TMA transfer to copy shared memory to global memory
if (threadIdx.x == 0) {
// Transpose tile inside matrix
cde::cp_async_bulk_tensor_2d_shared_to_global(&tensor_map_tr, y, x,
&smem_buffer_tr);
// Wait for TMA transfer to have finished reading shared memory.
// Create a "bulk async-group" out of the previous bulk copy operation.
cde::cp_async_bulk_commit_group();
// Wait for the group to have completed reading from shared memory.
cde::cp_async_bulk_wait_group_read<0>();
}
// Destroy barrier. This invalidates the memory region of the barrier. If
// further computations were to take place in the kernel, this allows the
// memory location of the shared memory barrier to be reused.
if (threadIdx.x == 0) {
(&bar)->~barrier();
}
}
This kernel archieves the following performance for transpose of a matrix of dimension 32768 x 32768:
Latency = 3.09955 ms
Bandwidth = 2771.35 GB/s
% of max = 83.9804 %
Conclusion
We saw that once we have the formula to obtain the indices from the swizzled indices it is pretty straightforward to implement matrix transpose in highly efficient way for Hopper architecture.
There is also a nice blogpost that uses CUTLASS to perform the same operation but i believe it is educational to implement the operation without any abstraction.
If you are interested in CUTLASS you can check out the Colfax blogpost on this blogpost.
All code can be found on my Github. I am happy to connect on Linkedin if you want to discuss CUDA or other things related to ML Sys and high performance computing.