How to use reasoning models with SGLang
In this document we will provide a hands-on resource for people who quickly want to onboard to SGLang.
SGLang is a highly performant inference engine for LLMs and scales well up to large number of GPUs.
We will use the new Qwen3 model series which enjoyed first day support on SGLang.
In this blogpost we will use the 8B model. If you are on a smaller GPU please check out one of the smaller Qwen models, they are equally great.
Setup develop environment
Use the following command to run a docker container which SGLang setup and ready to use
docker run -it --name h100_simon --gpus device=7 \
--shm-size 32g \
-v /.cache:/root/.cache \
--ipc=host \
lmsysorg/sglang:dev \
/bin/zsh
From now on we will work inside this docker container.
Note: I choose above device = 7, you may of course choose any device or all to use all available GPUs.
Basic inference
Use
python3 -m sglang.launch_server --model-path Qwen/Qwen3-8B
to spin up a server. Initially that will take some time because the model weights will be downloaded, afterwards the server start will be much quicker. For additional server arguments please refer to the corresponding doc.
After the server is up you will see in terminal:
The server is fired up and ready to roll!
We are now set to perform inference.
To use Qwen3 please execute the following program:
from openai import OpenAI
# Set OpenAI's API key and API base to use SGLang's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:30000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen/Qwen3-8B",
messages=[
{"role": "user", "content": "Give me a short introduction to large language models."},
],
max_tokens=32768,
temperature=0.6,
top_p=0.95,
extra_body={
"top_k": 20,
},
)
print("Chat response:", chat_response)
You will recieve the response
Chat response: ChatCompletion(id='f5f49f3ca0034271b847d960df16563e', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content="<think>\nOkay, the user wants a short introduction to large language models. Let me start by defining what they are. They're AI systems trained on massive amounts of text data. I should mention their ability to understand and generate human-like text. Maybe include some examples like GPT or BERT. Also, highlight their applications in tasks like answering questions, writing, coding, and more. Keep it concise but cover the key points. Avoid technical jargon so it's accessible. Make sure to note that they're part of the broader field of NLP. Check if there's anything else important, like their training process or significance. Alright, that should cover it.\n</think>\n\nLarge language models (LLMs) are advanced artificial intelligence systems trained on vast amounts of text data to understand and generate human-like language. They can perform tasks such as answering questions, writing stories, coding, and translating languages by recognizing patterns in text. These models, like GPT or BERT, leverage deep learning to process and produce coherent responses, making them powerful tools in natural language processing (NLP) and a cornerstone of modern AI applications.", refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None, reasoning_content=None), matched_stop=151645)], created=1746716570, model='Qwen/Qwen3-8B', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=227, prompt_tokens=18, total_tokens=245, completion_tokens_details=None, prompt_tokens_details=None))
An equivalent way of getting the response would be to use curl
curl http://localhost:30000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "Qwen/Qwen3-8B",
"messages": [
{"role": "user", "content": "Give me a short introduction to large language models."}
],
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20,
"max_tokens": 32768
}'
You will than recieve the response in the following format:
{"id":"25f606ceada843eb8d980114b0475d87","object":"chat.completion","created":1746716675,"model":"Qwen/Qwen3-8B","choices":[{"index":0,"message":{"role":"assistant","content":"<think>\nOkay, the user wants a short introduction to large language models. Let me start by defining what they are. I should mention that they are AI systems trained on vast amounts of text data. Then, maybe explain how they work, like using deep learning and neural networks. It's important to highlight their ability to understand and generate human-like text. I should also touch on their applications, such as answering questions, creating content, coding, etc. Oh, and maybe mention some examples like GPT or BERT. Wait, the user might not know specific models, so I should keep it general. Also, I need to keep it concise since they asked for a short intro. Let me make sure not to get too technical. Maybe include something about their scale, like the number of parameters. But don't go into too much detail. Alright, let me put that together in a clear, straightforward way.\n</think>\n\nLarge language models (LLMs) are advanced AI systems trained on vast amounts of text data to understand and generate human-like language. They use deep learning techniques, such as transformer architectures, to process and analyze patterns in text, enabling tasks like answering questions, creating content, coding, and even reasoning. These models, often with billions of parameters, excel at tasks requiring contextual understanding and can adapt to diverse applications, from customer service to research. Notable examples include models like GPT, BERT, and others developed by companies like OpenAI and Google. Their ability to mimic human language makes them powerful tools for automation, creativity, and problem-solving.","reasoning_content":null,"tool_calls":null},"logprobs":null,"finish_reason":"stop","matched_stop":151645}],"usage":{"prompt_tokens":18,"total_tokens":335,"completion_tokens":317,"prompt_tokens_details":null}}
Parsing reasoning content
We may want to separate reasoning content from the rest of the response.
SGLang offers the capability to do so by providing the additional server argument --reasoning-parser.
To start the model with reasoning parser please execute:
python3 -m sglang.launch_server --model-path Qwen/Qwen3-8B --reasoning-parser qwen3
We can than separate reasoning from the rest of the content as follows:
from openai import OpenAI
# Set OpenAI's API key and API base to use SGLang's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:30000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen/Qwen3-8B",
messages=[
{"role": "user", "content": "Give me a short introduction to large language models."},
],
max_tokens=32768,
temperature=0.6,
top_p=0.95,
extra_body={
"top_k": 20,
"separate_reasoning": True
},
)
print("==== Reasoning ====")
print(chat_response.choices[0].message.reasoning_content)
print("==== Text ====")
print(chat_response.choices[0].message.content)
This will give use
==== Reasoning ====
Okay, the user wants a short introduction to large language models. Let me start by defining what they are. They are AI systems trained on massive amounts of text data. I should mention their ability to understand and generate human-like text. Maybe include examples like GPT or BERT. Also, highlight their applications in various fields. Need to keep it concise but informative. Let me check if I'm missing any key points. Oh, maybe mention the training process and the scale of data. Avoid technical jargon to keep it accessible. Alright, that should cover the basics without being too lengthy.
==== Text ====
Large language models (LLMs) are advanced artificial intelligence systems trained on vast amounts of text data to understand and generate human-like language. These models, such as GPT or BERT, use deep learning techniques to recognize patterns, answer questions, and create coherent text across diverse topics. Their ability to process and generate natural language makes them valuable for tasks like translation, summarization, chatbots, and content creation. LLMs continue to evolve, driving innovations in fields like education, healthcare, and customer service.
For more details please see the documentation of the Reasoning parser.
Structured output
Structured output is an interesting application of LLMs. We can use them to structure previously unstructured data and bring it into a format that can further be processed.
The following script can generate structured output, after a server is started with reasoning-parser.
from openai import OpenAI
from pydantic import BaseModel, Field
# Set OpenAI's API key and API base to use SGLang's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:30000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
# Define the schema using Pydantic
class CapitalInfo(BaseModel):
name: str = Field(..., pattern=r"^\w+$", description="Name of the capital city")
population: int = Field(..., description="Population of the capital city")
response = client.chat.completions.create(
model="Qwen/Qwen3-8B",
messages=[
{
"role": "system",
"content": "Please extract the name and population of the given country as JSON schema."
},
{
"role": "user",
"content": "Please extract name and population of the Capital of France.",
},
],
temperature=0,
max_tokens=2048,
response_format={
"type": "json_schema",
"json_schema": {
"name": "foo",
# convert the pydantic model to json schema
"schema": CapitalInfo.model_json_schema(),
},
},
)
print(
f"reasoning content: {response.choices[0].message.reasoning_content}\n\ncontent: {response.choices[0].message.content}"
)
Here we use Pydantic to formulate our structure in a convenient way.
reasoning content: Okay, the user is asking for the name and population of the capital of France. Let me break this down.
First, I need to confirm which city is the capital of France. I know that France's capital is Paris. So the name part is straightforward.
Next, the population. I remember that Paris has a population of around 2.1 million people. But wait, I should check if that's the latest data. The most recent estimates might be a bit higher or lower. Let me think—maybe the 2023 estimate is about 2.16 million? Or is it 2.1 million? I think the commonly cited figure is approximately 2.1 million, but I should be precise.
Wait, the user might be expecting the exact number. Let me recall. The population of Paris is often cited as around 2.1 million, but the exact figure can vary. For example, the 2022 estimate was about 2.16 million. However, sometimes sources round it to 2.1 million for simplicity.
I need to make sure I'm not giving outdated information. If I can't recall the exact number, it's better to state the approximate figure. Also, the user might not need the most precise number, just a reasonable estimate.
So, putting it all together, the capital of France is Paris, and its population is approximately 2.1 million. I should present this as a JSON object with "name" and "population" keys. Let me double-check the structure to ensure it's correct. The JSON should have the name as a string and population as a number.
Wait, the user said "population of the Capital of France," so the capital is Paris, and the population is that of Paris. I need to make sure there's no confusion with the population of France as a country versus the capital city. The question specifically asks for the capital's population, so Paris is correct.
Alright, I think that's all. The JSON should be accurate and clear.
content: {
"name": "Paris",
"population": 2100000
}
For more see the corresponding SGLang doc.
Multi GPU usage
There are multiple reasons why we would like to use more than one GPU.
- The model doesn't fit onto one GPU.
- We want to leverage multiple GPUs to process inputs in parallel.
The first problem can be solved by tensor parellelism, i.e. we distribute the model weight in a sharded fashion onto multiple GPUs. Notice that this technique is mainly employed for memory constraints, not to get higher throughput.
The second problem can be solved by data parallelism, i.e. we replicate the model along multiple GPUs and send requests in parallel to one of them.
SGLangs router can be used to leverage multiple GPUs in a convenient way.
It can be installed via pip install sglang-router.
Let us modify the above docker start script to use multiple GPUs, i.e.
docker run -it --name h100_simon --gpus '"device=6,7"' \
--shm-size 32g \
-v /.cache:/root/.cache \
--ipc=host \
lmsysorg/sglang:dev \
/bin/zsh
Tensor parallel and data parallel size can be controlled via dp-size and tp-size server arguments.
Using the router starting in data parallel mode is as simple as
python3 -m sglang_router.launch_server --model-path Qwen/Qwen3-8B --dp-size 2
We will get notices that the process is finished successfully by a message like this:
✅ Serving workers on ["http://127.0.0.1:31000", "http://127.0.0.1:31186"]
Please note that you will need to fulfil dp_size * tp_size = #GPUs.
Let's simulate a heavy workload. Note that we don't tune for highest performance here. This is just to show that the router works as expected and processes the requests on both GPUs. Please observe the terminal where you started the router to understand better. To understand command line arguments please refer to bench_serving.py.
python3 -m sglang.bench_serving --backend sglang --dataset-name random --num-prompts 1000 --random-input 4096 --random-output 4096 --random-range-ratio 0.5
You may execute
watch nvidia-smi
and see both GPUs being heavily utilised:
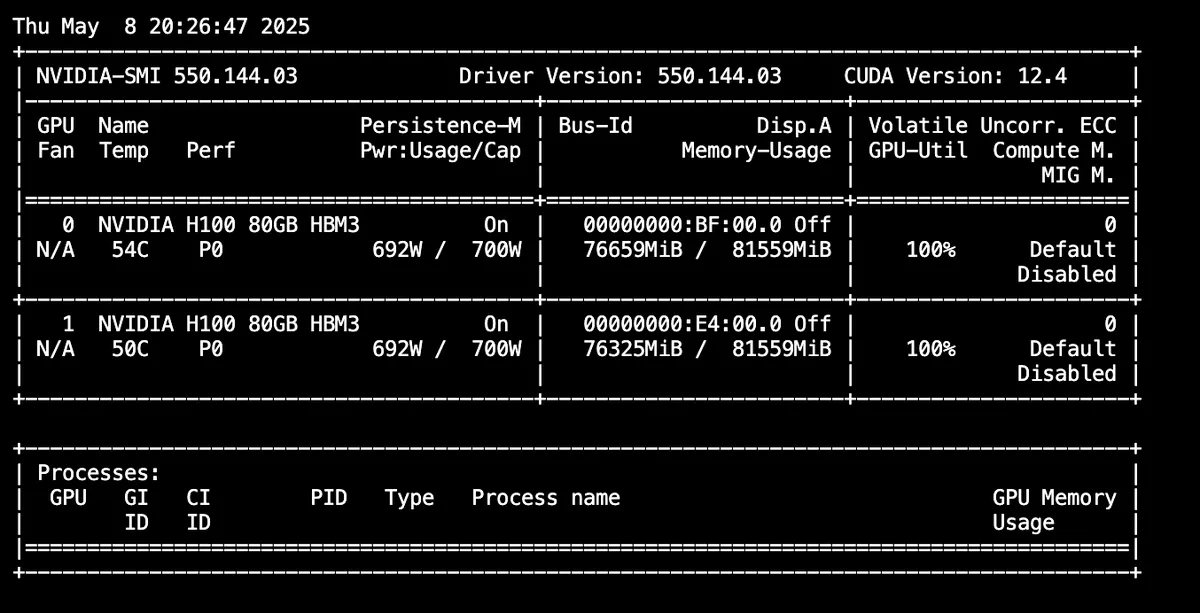
Conclusion
I hope this blogpost made SGLang and reasoning models in SGLang better understandable. If you have further questions please let me know. You can contact me via Linkedin.
There is multiple valuable resources on SGLang
- SGLang is OpenSource and naturally the codebase is a highly valuable resource.
- The documentation contains lots of examples. As well as the examples folder.
- The benchmark folder of the SGLang repo contains more involved examples.
- A technical deep dive is given in Code walkthrough of the Awesome-ML-Sys Tutorial repo.
- The SGLang Slack Channel is a very helpful community.