GPU L2 Cache Persistence
Introduction
On the GPU we have L2 cache as one part of Memory Hierarchy. L2 is shared by all Streaming Multiprocessors and can be leveraged to perform data sharing between warps. From Ampere on the L2 cache can be also used in following way: Assume we have certain part of input data that is accessed frequently. On NVIDIA this type of data access is called persistent. The opposite of persistent is called streaming. We can reserve part of L2 cache (on the NVIDIA H100 80GB HBM3, I performed the experiments on up to 31.25MB of the total 50MB of L2 memory) for the persistent data accesses.
This can bring good performance improvements in memory bound tasks. Below I show how to implement it and perform some benchmarks.
Code
Data Reset
Data Reset is the following operation.
__global__ void data_reset_kernel(const float4 *d_in, float4 *d_out, const int n, const int m) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n/4) d_out[i] = d_in[i % (m/4)];
}
It can be interpreted as the task "repeat a periodic signal until you reach the maximum output size". We assume m << n. It is obvious that this data access is persistent: We repeatedly access the elements in smaller array.
We can call such a kernel as follows:
void run_data_reset(const float* in, float* out, const int n, const int m, const int device_id) {
const size_t size_in = m * sizeof(float);
const size_t size_out = n * sizeof(float);
float *d_in, *d_out;
cudaStream_t stream;
cudaDeviceProp prop;
CHECK_CUDA_ERROR(cudaGetDeviceProperties(&prop, device_id));
std::cout << std::fixed << std::setprecision(2);
std::cout << "Running on device = " << device_id << std::endl;
std::cout << "In data size = " << (size_in) / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "Out data size = " << (size_out) / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "L2 cache size = " << prop.l2CacheSize / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "Maximum persistent L2 cache size = " << prop.persistingL2CacheMaxSize / (1024.0 * 1024.0) << "MB" << std::endl;
CHECK_CUDA_ERROR(cudaSetDevice(device_id));
CHECK_CUDA_ERROR(cudaMalloc((void**)&d_in, size_in));
CHECK_CUDA_ERROR(cudaMalloc((void**)&d_out, size_out));
CHECK_CUDA_ERROR(cudaMemcpy(d_in, in, size_in, cudaMemcpyHostToDevice));
CHECK_CUDA_ERROR(cudaStreamCreate(&stream));
const int threads_per_block = 1024;
const int blocks_per_grid = (n/4 + threads_per_block - 1) / threads_per_block;
data_reset_kernel<<<blocks_per_grid, threads_per_block, 0U, stream>>>(
reinterpret_cast<float4 *>(d_in), reinterpret_cast<float4 *>(d_out), n, m
);
CHECK_LAST_CUDA_ERROR();
CHECK_CUDA_ERROR(cudaStreamSynchronize(stream));
CHECK_CUDA_ERROR(cudaMemcpy(out, d_out, size_out, cudaMemcpyDeviceToHost));
CHECK_CUDA_ERROR(cudaFree(d_in));
CHECK_CUDA_ERROR(cudaFree(d_out));
CHECK_CUDA_ERROR(cudaStreamDestroy(stream));
}
If we want to reserve part of L2 for persistent access we can do that as such.
void run_data_reset_with_l2_persistence(const float* in, float* out, const int n, const int m, const int device_id) {
const size_t size_in = m * sizeof(float);
const size_t size_out = n * sizeof(float);
float *d_in, *d_out;
cudaStream_t stream;
cudaDeviceProp prop;
CHECK_CUDA_ERROR(cudaGetDeviceProperties(&prop, device_id));
std::cout << std::fixed << std::setprecision(2);
std::cout << "Running on device = " << device_id << std::endl;
std::cout << "In data size = " << (size_in) / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "Out data size = " << (size_out) / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "L2 cache size = " << prop.l2CacheSize / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "Maximum persistent L2 cache size = " << prop.persistingL2CacheMaxSize / (1024.0 * 1024.0) << "MB" << std::endl;
CHECK_CUDA_ERROR(cudaSetDevice(device_id));
CHECK_CUDA_ERROR(cudaMalloc((void**)&d_in, size_in));
CHECK_CUDA_ERROR(cudaMalloc((void**)&d_out, size_out));
CHECK_CUDA_ERROR(cudaMemcpy(d_in, in, size_in, cudaMemcpyHostToDevice));
CHECK_CUDA_ERROR(cudaStreamCreate(&stream));
size_t l2_max_cache_persistent = 8 * 1024 * 1024;//1 * 1024 * 1024;
std::cout << "Set Limit for persisting L2 cache size equal to " << l2_max_cache_persistent / (1024 * 1024) << "MB" << std::endl;
CHECK_CUDA_ERROR(cudaDeviceSetLimit(cudaLimitPersistingL2CacheSize, l2_max_cache_persistent));
std::cout << "Set stream attributes for persisting L2 cache." << std::endl;
cudaStreamAttrValue stream_attribute;
stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(d_in);
stream_attribute.accessPolicyWindow.num_bytes = l2_max_cache_persistent;
//stream_attribute.accessPolicyWindow.hitRatio = 1;
stream_attribute.accessPolicyWindow.hitRatio = std::min(l2_max_cache_persistent / ((float) size_in), 1.0f);
std::cout << "Hit Ratio = " << stream_attribute.accessPolicyWindow.hitRatio << std::endl;
stream_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting; // Type of access property on cache hit
stream_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming; // Type of access property on cache miss.
CHECK_CUDA_ERROR(cudaStreamSetAttribute(stream, cudaStreamAttributeAccessPolicyWindow, &stream_attribute));
const int threads_per_block = 1024;
const int blocks_per_grid = (n/4 + threads_per_block - 1) / threads_per_block;
data_reset_kernel<<<blocks_per_grid, threads_per_block, 0U, stream>>>(
reinterpret_cast<float4 *>(d_in), reinterpret_cast<float4 *>(d_out), n, m
);
CHECK_LAST_CUDA_ERROR();
CHECK_CUDA_ERROR(cudaStreamSynchronize(stream));
CHECK_CUDA_ERROR(cudaMemcpy(out, d_out, size_out, cudaMemcpyDeviceToHost));
CHECK_CUDA_ERROR(cudaFree(d_in));
CHECK_CUDA_ERROR(cudaFree(d_out));
CHECK_CUDA_ERROR(cudaStreamDestroy(stream));
}
The relevant part for the reservation is:
size_t l2_max_cache_persistent = 8 * 1024 * 1024;//1 * 1024 * 1024;
std::cout << "Set Limit for persisting L2 cache size equal to " << l2_max_cache_persistent / (1024 * 1024) << "MB" << std::endl;
CHECK_CUDA_ERROR(cudaDeviceSetLimit(cudaLimitPersistingL2CacheSize, l2_max_cache_persistent));
std::cout << "Set stream attributes for persisting L2 cache." << std::endl;
cudaStreamAttrValue stream_attribute;
stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(d_in);
stream_attribute.accessPolicyWindow.num_bytes = l2_max_cache_persistent;
//stream_attribute.accessPolicyWindow.hitRatio = 1;
stream_attribute.accessPolicyWindow.hitRatio = std::min(l2_max_cache_persistent / ((float) size_in), 1.0f);
std::cout << "Hit Ratio = " << stream_attribute.accessPolicyWindow.hitRatio << std::endl;
stream_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting; // Type of access property on cache hit
stream_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming; // Type of access property on cache miss.
We see that it is quite easy. We just set our configuration in the stream_attribute. Note that we dynamically adjust the hitRatio in case our input size exceeds the reserved persistent region in L2. For example if the size is double of the reserved size hitRatio = 0.5 etc. This is needed to achieve best performance and taken from the CUDA best practices guide.
I build my project with CMAKE and after compiling we can use following code to benchmark performance with NCU in the build directory. Here the first argument is the device we run on, the second argument is the size of output data and the last argument is size of persistent data.
# 2 MB
ncu --set full -o ../profiles/main_data_resetting_4096_2 ./main_data_resetting 1 1073741824 524288
ncu --set full -o ../profiles/main_data_resetting_persistence_4096_2 ./main_data_resetting 1 1073741824 524288
# 4 MB
ncu --set full -o ../profiles/main_data_resetting_4096_3 ./main_data_resetting 1 1073741824 1048576
ncu --set full -o ../profiles/main_data_resetting_persistence_4096_3 ./main_data_resetting 1 1073741824 1048576
# 8 MB
ncu --set full -o ../profiles/main_data_resetting_4096_4 ./main_data_resetting 1 1073741824 2097152
ncu --set full -o ../profiles/main_data_resetting_persistence_4096_4 ./main_data_resetting 1 1073741824 2097152
# 16 MB
ncu --set full -o ../profiles/main_data_resetting_4096_5 ./main_data_resetting 1 1073741824 4194304
ncu --set full -o ../profiles/main_data_resetting_persistence_4096_5 ./main_data_resetting 1 1073741824 4194304
Streaming and Persistent
The second benchmark mixes streaming and persistent data as described here:
__global__ void stream_and_persistent_kernel(const float4* __restrict__ d_in_persistent, const float4* __restrict__ d_in_streaming, float4* __restrict__ d_out, const int n, const int m) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
// Note n / 4 == n >> 2 and m / 4 == m >> 2, i % m == i & (m-1) if m 2^x
if (i < (n >> 2)) {
//float4 s = __ldlu(&d_in_streaming[i]);
float4 s = d_in_streaming[i];
float4 p = __ldcg(&d_in_persistent[i & ((m >> 2)-1)]);
d_out[i] = make_float4(p.x+s.x, p.y+s.y, p.z+s.z, p.w+s.w);
//atomicAdd(&d_out[i], s);
//atomicAdd(&d_out[i], p);
}
}
This can be interpreted as one periodic signal and one continuously evolving term. One might encounter such behavior if one wants to model some data signal and add a seasonality component to it.
The code is very similar to the above.
void run_stream_and_persistent(const float* in_persistent, const float* in_streaming, float* out, const int n, const int m, const int device_id) {
const size_t size_in = m * sizeof(float);
const size_t size_out = n * sizeof(float);
float *d_in_persistent, *d_in_streaming, *d_out;
cudaStream_t stream;
cudaDeviceProp prop;
CHECK_CUDA_ERROR(cudaGetDeviceProperties(&prop, device_id));
std::cout << std::fixed << std::setprecision(2);
std::cout << "Running on device = " << device_id << std::endl;
std::cout << "Persistent data size = " << (size_in) / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "Streaming data size = " << (size_out) / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "Out data size = " << (size_out) / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "L2 cache size = " << prop.l2CacheSize / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "Maximum persistent L2 cache size = " << prop.persistingL2CacheMaxSize / (1024.0 * 1024.0) << "MB" << std::endl;
CHECK_CUDA_ERROR(cudaSetDevice(device_id));
CHECK_CUDA_ERROR(cudaMalloc((void**)&d_in_persistent, size_in));
CHECK_CUDA_ERROR(cudaMalloc((void**)&d_in_streaming, size_out));
CHECK_CUDA_ERROR(cudaMalloc((void**)&d_out, size_out));
CHECK_CUDA_ERROR(cudaMemcpy(d_in_persistent, in_persistent, size_in, cudaMemcpyHostToDevice));
CHECK_CUDA_ERROR(cudaMemcpy(d_in_streaming, in_streaming, size_out, cudaMemcpyHostToDevice));
CHECK_CUDA_ERROR(cudaStreamCreate(&stream));
const int threads_per_block = 256;
const int blocks_per_grid = (n/4 + threads_per_block - 1) / threads_per_block;
stream_and_persistent_kernel<<<blocks_per_grid, threads_per_block, 0U, stream>>>(
reinterpret_cast<float4 *>(d_in_persistent), reinterpret_cast<float4 *>(d_in_streaming), reinterpret_cast<float4 *>(d_out), n, m
);
CHECK_LAST_CUDA_ERROR();
CHECK_CUDA_ERROR(cudaStreamSynchronize(stream));
CHECK_CUDA_ERROR(cudaMemcpy(out, d_out, size_out, cudaMemcpyDeviceToHost));
CHECK_CUDA_ERROR(cudaFree(d_in_persistent));
CHECK_CUDA_ERROR(cudaFree(d_in_streaming));
CHECK_CUDA_ERROR(cudaFree(d_out));
CHECK_CUDA_ERROR(cudaStreamDestroy(stream));
}
And reserving works the same as above as well.
void run_stream_and_persistent_with_l2_persistence(const float* in_persistent, const float* in_streaming, float* out, const int n, const int m, const int device_id) {
const size_t size_in = m * sizeof(float);
const size_t size_out = n * sizeof(float);
float *d_in_persistent, *d_in_streaming, *d_out;
cudaStream_t stream;
cudaDeviceProp prop;
CHECK_CUDA_ERROR(cudaGetDeviceProperties(&prop, device_id));
std::cout << std::fixed << std::setprecision(2);
std::cout << "Running on device = " << device_id << std::endl;
std::cout << "Persistent data size = " << (size_in) / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "Streaming data size = " << (size_out) / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "Out data size = " << (size_out) / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "L2 cache size = " << prop.l2CacheSize / (1024.0 * 1024.0) << "MB" << std::endl;
std::cout << "Maximum persistent L2 cache size = " << prop.persistingL2CacheMaxSize / (1024.0 * 1024.0) << "MB" << std::endl;
CHECK_CUDA_ERROR(cudaSetDevice(device_id));
CHECK_CUDA_ERROR(cudaMalloc((void**)&d_in_persistent, size_in));
CHECK_CUDA_ERROR(cudaMalloc((void**)&d_in_streaming, size_out));
CHECK_CUDA_ERROR(cudaMalloc((void**)&d_out, size_out));
CHECK_CUDA_ERROR(cudaMemcpy(d_in_persistent, in_persistent, size_in, cudaMemcpyHostToDevice));
CHECK_CUDA_ERROR(cudaMemcpy(d_in_streaming, in_streaming, size_out, cudaMemcpyHostToDevice));
CHECK_CUDA_ERROR(cudaStreamCreate(&stream));
size_t l2_max_cache_persistent = 8 * 1024 * 1024;//1 * 1024 * 1024;
std::cout << "Set Limit for persisting L2 cache size equal to " << l2_max_cache_persistent / (1024 * 1024) << "MB" << std::endl;
CHECK_CUDA_ERROR(cudaDeviceSetLimit(cudaLimitPersistingL2CacheSize, l2_max_cache_persistent));
std::cout << "Set stream attributes for persisting L2 cache." << std::endl;
cudaStreamAttrValue stream_attribute;
stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(d_in_persistent);
stream_attribute.accessPolicyWindow.num_bytes = l2_max_cache_persistent;
//stream_attribute.accessPolicyWindow.hitRatio = 1;
stream_attribute.accessPolicyWindow.hitRatio = std::min(l2_max_cache_persistent / ((float) size_in), 1.0f);
std::cout << "Hit Ratio = " << stream_attribute.accessPolicyWindow.hitRatio << std::endl;
stream_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting; // Type of access property on cache hit
stream_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming; // Type of access property on cache miss.
CHECK_CUDA_ERROR(cudaStreamSetAttribute(stream, cudaStreamAttributeAccessPolicyWindow, &stream_attribute));
const int threads_per_block = 256;
const int blocks_per_grid = (n/4 + threads_per_block - 1) / threads_per_block;
stream_and_persistent_kernel<<<blocks_per_grid, threads_per_block, 0U, stream>>>(
reinterpret_cast<float4 *>(d_in_persistent), reinterpret_cast<float4 *>(d_in_streaming), reinterpret_cast<float4 *>(d_out), n, m
);
CHECK_LAST_CUDA_ERROR();
CHECK_CUDA_ERROR(cudaStreamSynchronize(stream));
CHECK_CUDA_ERROR(cudaMemcpy(out, d_out, size_out, cudaMemcpyDeviceToHost));
CHECK_CUDA_ERROR(cudaFree(d_in_persistent));
CHECK_CUDA_ERROR(cudaFree(d_in_streaming));
CHECK_CUDA_ERROR(cudaFree(d_out));
CHECK_CUDA_ERROR(cudaStreamDestroy(stream));
}
Benchmarking can again be done as follows from the build directory. Here the first argument is the device we run on, the second argument is the size of output data and streaming data and the last argument is the size of persistent data.
# 2 MB
ncu --set full -o ../profiles/main_stream_4096_2 ./main_stream 1 1073741824 524288
ncu --set full -o ../profiles/main_stream_and_persistent_4096_2 ./main_stream_and_persistent 1 1073741824 524288
# 4 MB
ncu --set full -o ../profiles/main_stream_4096_3 ./main_stream 1 1073741824 1048576
ncu --set full -o ../profiles/main_stream_and_persistent_4096_3 ./main_stream_and_persistent 1 1073741824 1048576
# 8 MB
ncu --set full -o ../profiles/main_stream_4096_4 ./main_stream 1 1073741824 2097152
ncu --set full -o ../profiles/main_stream_and_persistent_4096_4 ./main_stream_and_persistent 1 1073741824 2097152
# 16 MB
ncu --set full -o ../profiles/main_stream_4096_5 ./main_stream 1 1073741824 4194304
ncu --set full -o ../profiles/main_stream_and_persistent_4096_5 ./main_stream_and_persistent 1 1073741824 4194304
Benchmark results
Only persistent input data
For the kernels that reserve L2 cache for persistence we fix the reserved memory as 8MB. First we perform an experiment with only persistent data. I.e. we perform the operation:
__global__ void data_reset_kernel(const float4 *d_in, float4 *d_out, const int n, const int m) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n/4) d_out[i] = d_in[i % (m/4)];
}
We keep the output array fixed at a size of 4096MB and vary the size of the persistent input array to be 2MB, 4MB, 8MB, 16MB. All experiments are performed on NVIDIA H100 80GB HBM3 which has 50MB of L2 Cache of which 31.25MB can be reserved for persistent access.
The results are as follows:
| Data Size | Without L2 Cache Reservation | With L2 Cache Reservation | Speedup |
|---|---|---|---|
| 2MB | 1.31ms | 1.31ms | 1.000x |
| 4MB | 1.46ms | 1.46ms | 1.000x |
| 8MB | 1.64ms | 1.64ms | 1.000x |
| 16MB | 2.44ms | 2.43ms | 1.004x |
I guess that is the case because there is no streaming data that can "steal" L2 cache from persistent data anyway. So the benefit from reserving it for persisting accesses is not really visible.
See for example here where I compare the "with persistent cache reserve" approach to the naive approach. Both of them perform similarly in numbers and there is not a huge difference in how they leverage the L2 cache.
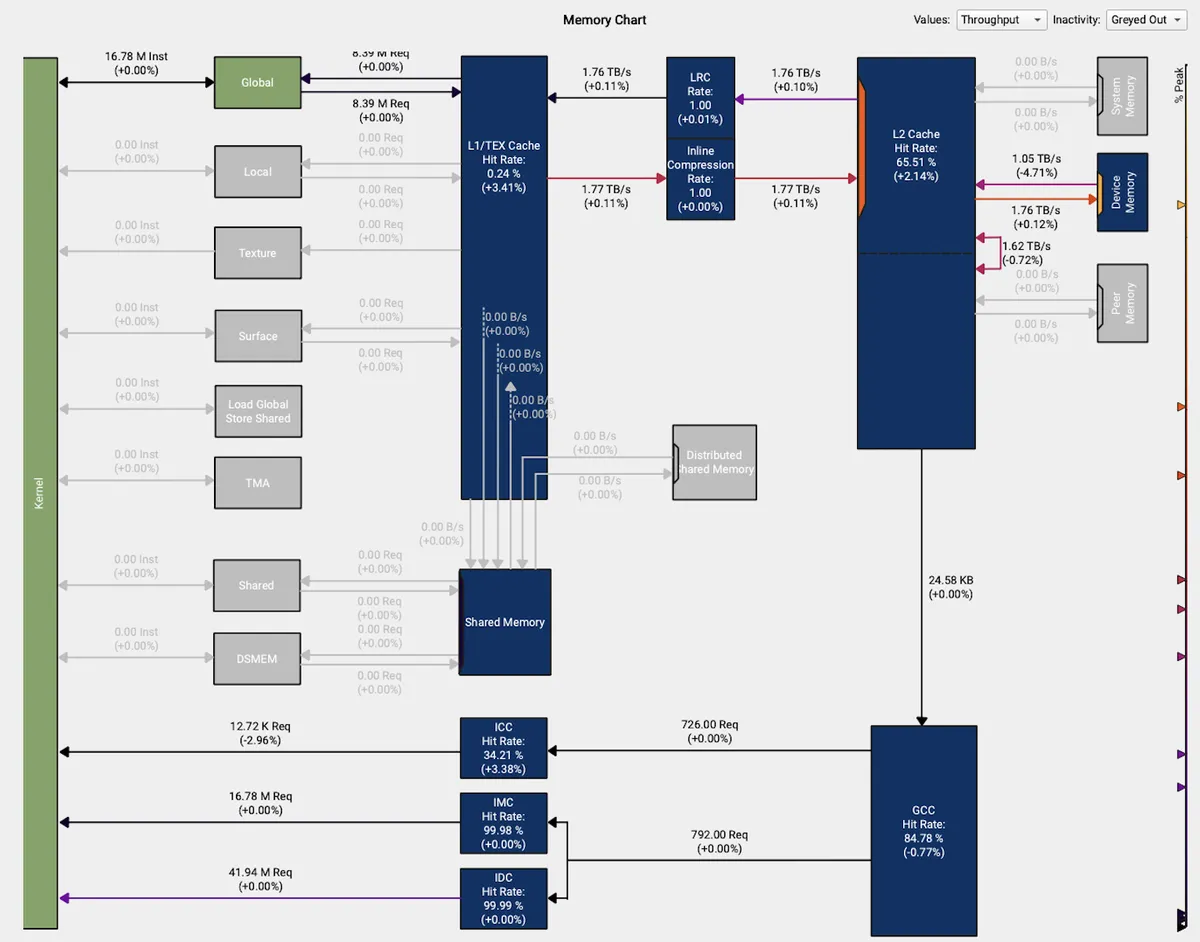
Persistent and Streaming input data
For the kernels that reserve L2 cache for persistence we fix the reserved memory as 8MB. Now we perform an experiment where we have streaming data (4096MB) and persistent data of the same varying size of input as above. We perform the following operation
__global__ void stream_and_persistent_kernel(const float4* __restrict__ d_in_persistent, const float4* __restrict__ d_in_streaming, float4* __restrict__ d_out, const int n, const int m) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
// Note n / 4 == n >> 2 and m / 4 == m >> 2, i % m == i & (m-1) if m 2^x
if (i < (n >> 2)) {
//float4 s = __ldlu(&d_in_streaming[i]);
float4 s = d_in_streaming[i];
float4 p = __ldcg(&d_in_persistent[i & ((m >> 2)-1)]);
d_out[i] = make_float4(p.x+s.x, p.y+s.y, p.z+s.z, p.w+s.w);
//atomicAdd(&d_out[i], s);
//atomicAdd(&d_out[i], p);
}
}
Note that in the kernel we perform compiler hint T __ldcg(const T* address); in the PTX docs this is explained:
Cache at global level (cache in L2 and below, not L1).
Use ld.cg to cache loads only globally, bypassing the L1 cache, and cache only in the L2 cache.
I also tried the intrinsics for streaming data. However this didn't have a positive influence on performance. Another experiment on the kernel level I tried was to use the atomicAdd to avoid splitting up the addition into 4 float adds and perform one add on float4 but this had very poor performance.
The results are as follows:
| Data Size | Without L2 Cache Reservation | With L2 Cache Reservation | Speedup |
|---|---|---|---|
| 2MB | 2.86ms | 2.81ms | 1.018x |
| 4MB | 2.97ms | 2.81ms | 1.057x |
| 8MB | 3.26ms | 2.81ms | 1.160x |
| 16MB | 4.12ms | 3.76ms | 1.096x |
We see that the overall effect of the reservation is now much higher than before. That is because we can help the GPU to figure out where persistent data resides. The speedup is quite significant depending on the size of the persistent cache:
Speedup = Time_baseline / Time_optimized
which gives us up to 1.160x. Even for 16MB where we adjust the hit ratio to 0.5 because of the size of persistent input data we get a decent speedup by 1.096x. Note that this is nice because it shows that even if we suspect our data to be persistent but exceed the maximum reservable persistent L2 cache size we should anyway reserve it and adjust hit ratio accordingly.
This is also visible from the profiler (here comparing for 16MB input).
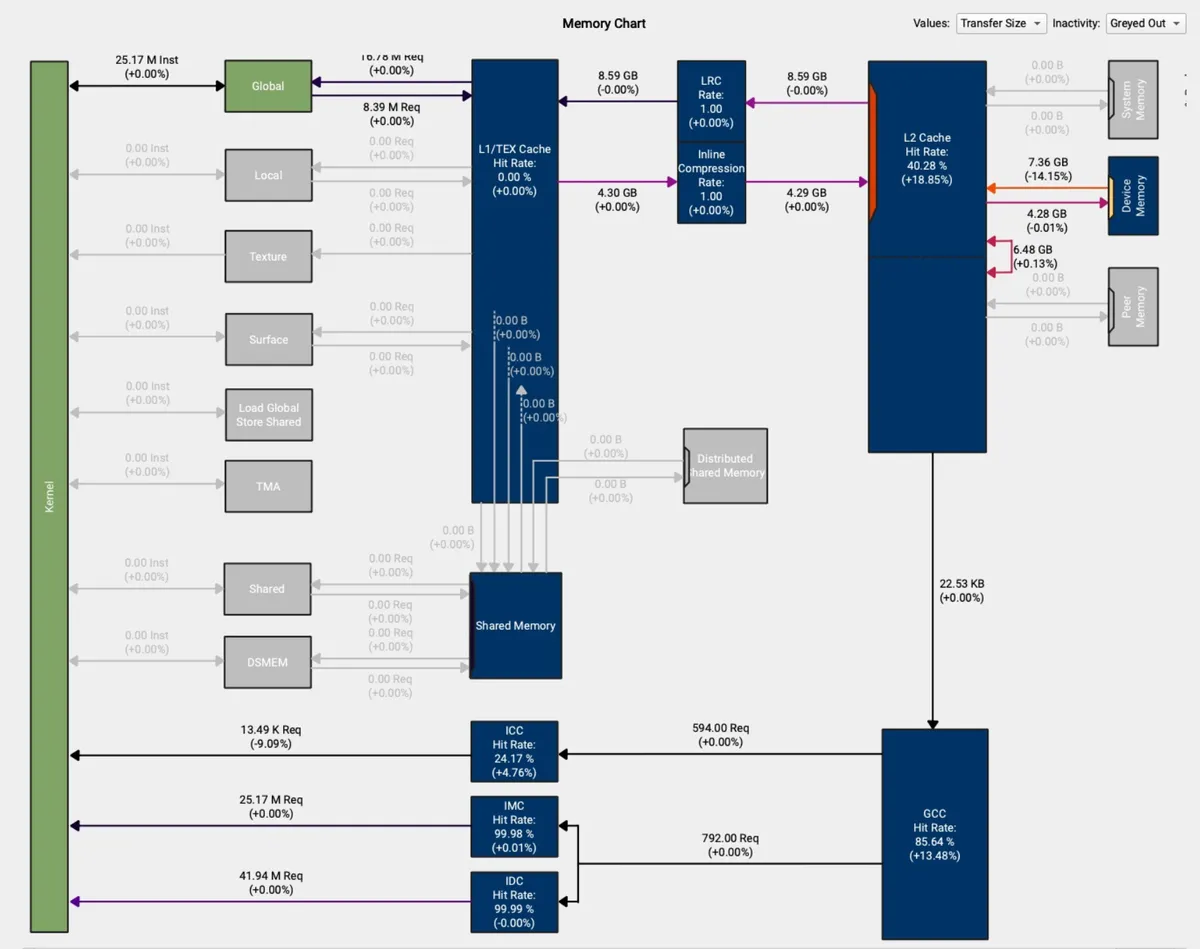
We see that our L2 Cache Hit Rate is significantly higher.
Conclusion
We have seen that in the presence of persistent data it can bring good speedup if we reserve a dedicated part of the L2 for the persistent accesses. We see that L2 cache persistence works best when streaming and persistent data compete for cache space. Without this competition, the benefits are minimal.
The performance improvements we observed show this technique can be quite useful for memory-bound kernels with mixed access patterns.
Even when persistent data exceeds available L2 cache space, partial reservation with adjusted hitRatio still provides benefits. This makes the technique practical for varying dataset sizes. I am curious to share further ideas on my Linkedin. The whole code can be found in my Github repo.
This discussion was inspired by the discussion here