CuTeDSL on Hopper - Pipelining
In the previous blogpost we learned about WGMMA and TMA atoms and how they are created in CuTeDSL. Here we will continue to analyse the dense_gemm.py example for Hopper. In this blogpost the focus will be on the kernel method. Note that for simplicity we will not consider Thread Block Clustering which is another new concept for Hopper to avoid overloading the mental burden in this blogpost.
kernel
All these arguments should look familiar. The tensors (i.e. m_{A|B|C}) have corresponding tma_atoms for transfer from GMEM -> SMEM (for A and B) or SMEM -> GMEM (for C). We furthermore have layouts for shared memory in stages and the tiler on the thread block level.
@cute.kernel
def kernel(
self,
tma_atom_a: cute.CopyAtom,
mA_mkl: cute.Tensor,
tma_atom_b: cute.CopyAtom,
mB_nkl: cute.Tensor,
tma_atom_c: cute.CopyAtom,
mC_mnl: cute.Tensor,
tiled_mma: cute.TiledMma,
cta_layout_mnk: cute.Layout,
a_smem_layout_staged: cute.ComposedLayout,
b_smem_layout_staged: cute.ComposedLayout,
epi_smem_layout_staged: cute.ComposedLayout,
):
We begin by prefetching the TMA descriptor associated with the TMA Atoms. The tma_descriptor contains information for the TMA instruction about layouts of source and destination of copy operation etc. For more see the corresponding section in CUDA C++ Guide.
if warp_idx == 0:
cute.nvgpu.cpasync.prefetch_descriptor(tma_atom_a)
cute.nvgpu.cpasync.prefetch_descriptor(tma_atom_b)
Do allocate bytes which are copied in one TMA instruction we slice into the layouts for A and B in SMEM. That is because the last mode simply corresponds to the number of stages.
a_smem_layout = cute.slice_(a_smem_layout_staged, (None, None, 0))
b_smem_layout = cute.slice_(b_smem_layout_staged, (None, None, 0))
tma_copy_bytes = cute.size_in_bytes(
self.a_dtype, a_smem_layout
) + cute.size_in_bytes(self.b_dtype, b_smem_layout)
Initialisation of SMEM can be done via the SmemAllocator.
smem = cutlass.utils.SmemAllocator()
storage = smem.allocate(self.shared_storage)
We initialise a Consumer/Producer Pipeline here.
# mbar arrays
mainloop_pipeline_array_ptr = storage.mainloop_pipeline_array_ptr.data_ptr()
# Threads/warps participating in this pipeline
mainloop_pipeline_producer_group = pipeline.CooperativeGroup(
pipeline.Agent.Thread
)
# Each warp will constribute to the arrive count with the number of mcast size
mcast_size = self.num_mcast_ctas_a + self.num_mcast_ctas_b - 1
num_warps = self.threads_per_cta // 32
consumer_arrive_cnt = mcast_size * num_warps
mainloop_pipeline_consumer_group = pipeline.CooperativeGroup(
pipeline.Agent.Thread, consumer_arrive_cnt
)
cta_layout_vmnk = cute.make_layout((1, *cta_layout_mnk.shape))
mainloop_pipeline = pipeline.PipelineTmaAsync.create(
barrier_storage=mainloop_pipeline_array_ptr,
num_stages=self.ab_stage,
producer_group=mainloop_pipeline_producer_group,
consumer_group=mainloop_pipeline_consumer_group,
tx_count=tma_copy_bytes,
cta_layout_vmnk=cta_layout_vmnk,
)
Let us look at how PipelineTmaAsync is described in the code base and than elaborate on that.
class PipelineTmaAsync(PipelineAsync):
"""
PipelineTmaAsync is used for TMA producers and AsyncThread consumers (e.g. Hopper mainloops).
"""
GPUs have specialised units, so called Tensorcores, to perform computation like WGMMA highly efficent. However they are oftentimes limited by bandwidth of Memory transfer from GMEM -> SMEM. It is therefore a good idea to overlap the transfer and computation in a way that can be depicted like so:
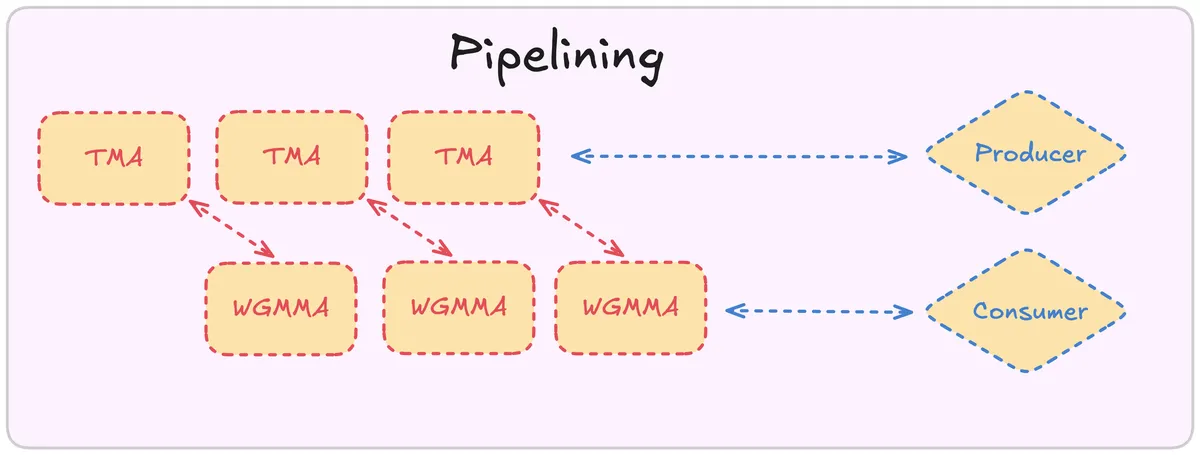
Next step is to allocate empty tensors corresponding to Layout and Swizzling of the TMA atoms
sa = storage.sa.get_tensor(
a_smem_layout_staged.outer, swizzle=a_smem_layout_staged.inner
)
sb = storage.sb.get_tensor(
b_smem_layout_staged.outer, swizzle=b_smem_layout_staged.inner
)
sc_ptr = cute.recast_ptr(
sa.iterator, epi_smem_layout_staged.inner, dtype=self.c_dtype
)
sc = cute.make_tensor(sc_ptr, epi_smem_layout_staged.outer)
We get the Tiles for our current Blocks
# (bM, bK, RestK)
gA_mkl = cute.local_tile(
mA_mkl, self.tile_shape_mnk, tile_coord_mnkl, proj=(1, None, 1)
)
# (bN, bK, RestK)
gB_nkl = cute.local_tile(
mB_nkl, self.tile_shape_mnk, tile_coord_mnkl, proj=(None, 1, 1)
)
# (bM, bN)
gC_mnl = cute.local_tile(
mC_mnl, self.tile_shape_mnk, tile_coord_mnkl, proj=(1, 1, None)
)
Note that we have a grid with
x-direction: M/bM blocks
y-direction: N/bN blocks
z-direction: L blocks
where L is the batch size, i.e. the number of matrices we want to multiply batchwise.
We'll than get a tensor of shape (bM, bK, K/bK) for A and (bN, bK, K/bK) for B. For C we get a local tile of (bM, bN).
Remember that WGMMA is a W(arp)G(group)MMA. We use therefore warp_group_thread_layout to partiton_C. Remember than partition = composing with TV Layout -> Slicing.
warp_group_idx = cute.arch.make_warp_uniform(
tidx // self.num_threads_per_warp_group
)
warp_group_thread_layout = cute.make_layout(
self.mma_warp_groups, stride=self.num_threads_per_warp_group
)
thr_mma = tiled_mma.get_slice(warp_group_thread_layout(warp_group_idx))
tCgC = thr_mma.partition_C(gC_mnl)
We partition A and B using tma_partition. Note that t{A|B}s{A|B} corresponds to tensors residing in SMEM and t{A|B}g{A|B} corresponds to tensors residing in GMEM.
a_cta_layout = cute.make_layout(cute.slice_(cta_layout_mnk, (0, None, 0)).shape)
a_cta_crd = cluster_coord_mnk[1]
sa_for_tma_partition = cute.group_modes(sa, 0, 2)
gA_for_tma_partition = cute.group_modes(gA_mkl, 0, 2)
tAsA, tAgA_mkl = cute.nvgpu.cpasync.tma_partition(
tma_atom_a,
a_cta_crd,
a_cta_layout,
sa_for_tma_partition,
gA_for_tma_partition,
)
# TMA load B partition_S/D
b_cta_layout = cute.make_layout(cute.slice_(cta_layout_mnk, (None, 0, 0)).shape)
b_cta_crd = cluster_coord_mnk[0]
sb_for_tma_partition = cute.group_modes(sb, 0, 2)
gB_for_tma_partition = cute.group_modes(gB_nkl, 0, 2)
tBsB, tBgB_nkl = cute.nvgpu.cpasync.tma_partition(
tma_atom_b,
b_cta_crd,
b_cta_layout,
sb_for_tma_partition,
gB_for_tma_partition,
)
group_modes will do exactly what it name says.It groups a range of modes from the input object into a single mode. For example
layout = make_layout((2, 3, 4, 5))
grouped_layout = group_modes(layout, 1, 3) # Layout with shape (2, (3, 4), 5)
Here it has the effect to separate the stage mode from the rest (where the rest is the SMEM Layout Atom). For GMEM it has same effect, as here the last mode will give use the number of Tiles we need to loop over to cover the whole K axis.
We'll allocate the registers (fragments).
tCsA = thr_mma.partition_A(sa)
tCsB = thr_mma.partition_B(sb)
tCrA = tiled_mma.make_fragment_A(tCsA)
tCrB = tiled_mma.make_fragment_B(tCsB)
acc_shape = tCgC.shape
accumulators = cute.make_fragment(acc_shape, self.acc_dtype)
Using our pipeline we create a PipelineState. We'll use the last mode of gA_mkl to obtain the number of k tiles. We'll than calculate the number of tiles to prefetch by taking the minimum of number of stages and tiles. We initialise a producer state which will keep track of the index and phase bit needed for TMA instruction internally.
k_tile_cnt = cute.size(gA_mkl, mode=[2])
prefetch_k_tile_cnt = cutlass.max(cutlass.min(self.ab_stage, k_tile_cnt), 0)
mainloop_producer_state = pipeline.make_pipeline_state(
pipeline.PipelineUserType.Producer, self.ab_stage
)
We do prefetch for the above defined number of tiles to prefetch.
Note that here we need the Producer because we copy over Tiles.
producer_acquire: conditionally waits on buffer empty and sets the transaction barriertAgA_k: Obtain by indexing into the correspondingtiletAsA_pipe: Obtain by indexing into the correspondingshape- Copy
tilefromGMEMtostageinSMEMforAandB advancethe state. This will updatecountandindexas well perform thephaseshift.
if warp_idx == 0:
# /////////////////////////////////////////////////////////////////////////////
# Prefetch TMA load
# /////////////////////////////////////////////////////////////////////////////
for prefetch_idx in cutlass.range(prefetch_k_tile_cnt, unroll=1):
# /////////////////////////////////////////////////////////////////////////////
# Wait for A/B buffers to be empty before loading into them
# Also sets the transaction barrier for the A/B buffers
# /////////////////////////////////////////////////////////////////////////////
mainloop_pipeline.producer_acquire(mainloop_producer_state)
# /////////////////////////////////////////////////////////////////////////////
# Slice to global/shared memref to current k_tile
# /////////////////////////////////////////////////////////////////////////////
tAgA_k = tAgA_mkl[(None, mainloop_producer_state.count)]
tAsA_pipe = tAsA[(None, mainloop_producer_state.index)]
tBgB_k = tBgB_nkl[(None, mainloop_producer_state.count)]
tBsB_pipe = tBsB[(None, mainloop_producer_state.index)]
# /////////////////////////////////////////////////////////////////////////////
# TMA load A/B
# /////////////////////////////////////////////////////////////////////////////
cute.copy(
tma_atom_a,
tAgA_k,
tAsA_pipe,
tma_bar_ptr=mainloop_pipeline.producer_get_barrier(
mainloop_producer_state
),
mcast_mask=a_mcast_mask,
)
cute.copy(
tma_atom_b,
tBgB_k,
tBsB_pipe,
tma_bar_ptr=mainloop_pipeline.producer_get_barrier(
mainloop_producer_state
),
mcast_mask=b_mcast_mask,
)
# Mainloop pipeline's producer commit is a NOP
mainloop_pipeline.producer_commit(mainloop_producer_state)
mainloop_producer_state.advance()
We initialise two Producers, one for reading and one for releasing. We calculate the number of k_blocks to be equal to the last mode of tCrA.
Let's take a look at our tiled_mma_atom:
MMA Atom
ThrID: 128:1
Shape MNK: (64,128,16)
TV Layout A: (128,(64,16)):(0,(1,64))
TV Layout B: (128,(128,16)):(0,(1,128))
TV Layout C: ((4,8,4),(2,2,16)):((128,1,16),(64,8,512))
This shows that we perform M=64, N =128, K=16 op for WGMMA. That corresponds to the shapes of the matrices that will get collectively multiplied in a warp group. The number of blocks is simply bK/16, i.e. we accumulate progressively.
We'll do that calculation in stages and advance after one stage is finished. We saw above that stages correspond to Tiles and hence we Tile the Tiles into smaller tiles of width 16 as explained above. That's why we have 2 loops. In this example we do the Prologue only for one stage. The Prologue is necessary to initialise the accumulators appropriately.
Further note: We initialize
tiled_mma.set(cute.nvgpu.warpgroup.Field.ACCUMULATE, False)
And update after the first GEMM. This avoids accumulating into a random value.
k_pipe_mmas = 1
mainloop_consumer_read_state = pipeline.make_pipeline_state(
pipeline.PipelineUserType.Consumer, self.ab_stage
)
mainloop_consumer_release_state = pipeline.make_pipeline_state(
pipeline.PipelineUserType.Consumer, self.ab_stage
)
peek_ab_full_status = cutlass.Boolean(1)
if mainloop_consumer_read_state.count < k_tile_cnt:
peek_ab_full_status = mainloop_pipeline.consumer_try_wait(
mainloop_consumer_read_state
)
tiled_mma.set(cute.nvgpu.warpgroup.Field.ACCUMULATE, False)
num_k_blocks = cute.size(tCrA, mode=[2])
for k_tile in cutlass.range_constexpr(k_pipe_mmas):
# Wait for A/B buffer to be ready
mainloop_pipeline.consumer_wait(
mainloop_consumer_read_state, peek_ab_full_status
)
cute.nvgpu.warpgroup.fence()
for k_block_idx in cutlass.range(num_k_blocks, unroll_full=True):
k_block_coord = (
None,
None,
k_block_idx,
mainloop_consumer_read_state.index,
)
tCrA_1phase = tCrA[k_block_coord]
tCrB_1phase = tCrB[k_block_coord]
cute.gemm(
tiled_mma,
accumulators,
tCrA_1phase,
tCrB_1phase,
accumulators,
)
tiled_mma.set(cute.nvgpu.warpgroup.Field.ACCUMULATE, True)
cute.nvgpu.warpgroup.commit_group()
mainloop_consumer_read_state.advance()
peek_ab_full_status = cutlass.Boolean(1)
if mainloop_consumer_read_state.count < k_tile_cnt:
peek_ab_full_status = mainloop_pipeline.consumer_try_wait(
mainloop_consumer_read_state
)
What than comes is called the main loop.
The main loop is not difficult to understand if we understood the prologue and prefetch part.
It can be separated into two distinct phases that correspond to the Pipeline pattern I drew above:
Calculation
In the first phase we process a tile bK. We see again that we have the same pattern as above where we further get subtiles because thats what WGMMAdemands from us. We release the consumer and advance the two consumer states.
Memory Load
We have processed a Tile. That means we can schedule the next Load. This makes sure that our Tensor Cores are always busy and don't sit idle waiting for memory transfer to complete! After we processed the Tile we advance the producer state!
for k_tile in cutlass.range(k_pipe_mmas, k_tile_cnt, 1, unroll=1):
# /////////////////////////////////////////////////////////////////////////////
# Wait for TMA copies to complete
# /////////////////////////////////////////////////////////////////////////////
mainloop_pipeline.consumer_wait(
mainloop_consumer_read_state, peek_ab_full_status
)
# /////////////////////////////////////////////////////////////////////////////
# WGMMA
# /////////////////////////////////////////////////////////////////////////////
cute.nvgpu.warpgroup.fence()
for k_block_idx in cutlass.range(num_k_blocks, unroll_full=True):
k_block_coord = (
None,
None,
k_block_idx,
mainloop_consumer_read_state.index,
)
tCrA_1phase = tCrA[k_block_coord]
tCrB_1phase = tCrB[k_block_coord]
cute.gemm(
tiled_mma,
accumulators,
tCrA_1phase,
tCrB_1phase,
accumulators,
)
cute.nvgpu.warpgroup.commit_group()
# Wait on the wgmma barrier for previous k_pipe_mmas wgmmas to complete
cute.nvgpu.warpgroup.wait_group(k_pipe_mmas)
mainloop_pipeline.consumer_release(mainloop_consumer_release_state)
mainloop_consumer_read_state.advance()
mainloop_consumer_release_state.advance()
peek_ab_full_status = cutlass.Boolean(1)
if mainloop_consumer_read_state.count < k_tile_cnt:
peek_ab_full_status = mainloop_pipeline.consumer_try_wait(
mainloop_consumer_read_state
)
# /////////////////////////////////////////////////////////////////////////////
# TMA load
# /////////////////////////////////////////////////////////////////////////////
if warp_idx == 0 and mainloop_producer_state.count < k_tile_cnt:
# /////////////////////////////////////////////////////////////////////////////
# Wait for A/B buffers to be empty before loading into them
# Also sets the transaction barrier for the A/B buffers
# /////////////////////////////////////////////////////////////////////////////
mainloop_pipeline.producer_acquire(mainloop_producer_state)
# /////////////////////////////////////////////////////////////////////////////
# Slice to global/shared memref to current k_tile
# /////////////////////////////////////////////////////////////////////////////
tAgA_k = tAgA_mkl[(None, mainloop_producer_state.count)]
tAsA_pipe = tAsA[(None, mainloop_producer_state.index)]
tBgB_k = tBgB_nkl[(None, mainloop_producer_state.count)]
tBsB_pipe = tBsB[(None, mainloop_producer_state.index)]
# /////////////////////////////////////////////////////////////////////////////
# TMA load A/B
# /////////////////////////////////////////////////////////////////////////////
cute.copy(
tma_atom_a,
tAgA_k,
tAsA_pipe,
tma_bar_ptr=mainloop_pipeline.producer_get_barrier(
mainloop_producer_state
),
mcast_mask=a_mcast_mask,
)
cute.copy(
tma_atom_b,
tBgB_k,
tBsB_pipe,
tma_bar_ptr=mainloop_pipeline.producer_get_barrier(
mainloop_producer_state
),
mcast_mask=b_mcast_mask,
)
# Mainloop pipeline's producer commit is a NOP
mainloop_pipeline.producer_commit(mainloop_producer_state)
mainloop_producer_state.advance()
Now we want to copy over the results to GMEM. We will do this in a two step approach and in stages (self.epi_stages being the number of stages).
RMEM -> SMEM
We'll use StMatrixx8x8x16Op which is a store_matrix operation to efficiently copy matrices. I wrote a Blog on these instructions which you might want to check out for more background.
SMEM -> GMEM
This is done using the TMA again.
Note that we need to use barriers. This is necessary because obviously the store to SMEM must have been finished when we want to schedule it's transfer to GMEM via TMA.
cute.nvgpu.warpgroup.wait_group(0)
if cute.size(self.cluster_shape_mnk) > 1:
# Wait for all threads in the cluster to finish, avoid early release of smem
cute.arch.cluster_arrive()
cute.arch.cluster_wait()
else:
# For cluster that has a single thread block, it might have more than one warp groups.
# Wait for all warp groups in the thread block to finish, because smem for tensor A in
# the mainloop is reused in the epilogue.
cute.arch.sync_threads()
copy_atom_r2s = sm90_utils.sm90_get_smem_store_op(
self.c_layout,
elem_ty_d=self.c_dtype,
elem_ty_acc=self.acc_dtype,
)
copy_atom_C = cute.make_copy_atom(
cute.nvgpu.warp.StMatrix8x8x16bOp(
self.c_layout.is_m_major_c(),
4,
),
self.c_dtype,
)
tiled_copy_C_Atom = cute.make_tiled_copy_C_atom(copy_atom_C, tiled_mma)
tiled_copy_r2s = cute.make_tiled_copy_S(
copy_atom_r2s,
tiled_copy_C_Atom,
)
# (R2S, R2S_M, R2S_N, PIPE_D)
thr_copy_r2s = tiled_copy_r2s.get_slice(tidx)
tRS_sD = thr_copy_r2s.partition_D(sc)
# (R2S, R2S_M, R2S_N)
tRS_rAcc = tiled_copy_r2s.retile(accumulators)
# Allocate D registers.
rD_shape = cute.shape(thr_copy_r2s.partition_S(sc))
tRS_rD_layout = cute.make_layout(rD_shape[:3])
tRS_rD = cute.make_fragment_like(tRS_rD_layout, self.acc_dtype)
size_tRS_rD = cute.size(tRS_rD)
sepi_for_tma_partition = cute.group_modes(sc, 0, 2)
tcgc_for_tma_partition = cute.zipped_divide(gC_mnl, self.epi_tile)
bSG_sD, bSG_gD = cute.nvgpu.cpasync.tma_partition(
tma_atom_c,
0,
cute.make_layout(1),
sepi_for_tma_partition,
tcgc_for_tma_partition,
)
epi_tile_num = cute.size(tcgc_for_tma_partition, mode=[1])
epi_tile_shape = tcgc_for_tma_partition.shape[1]
for epi_idx in cutlass.range(epi_tile_num, unroll=epi_tile_num):
# Copy from accumulators to D registers
for epi_v in cutlass.range_constexpr(size_tRS_rD):
tRS_rD[epi_v] = tRS_rAcc[epi_idx * size_tRS_rD + epi_v]
# Type conversion
tRS_rD_out = cute.make_fragment_like(tRS_rD_layout, self.c_dtype)
acc_vec = tRS_rD.load()
tRS_rD_out.store(acc_vec.to(self.c_dtype))
# Copy from D registers to shared memory
epi_buffer = epi_idx % cute.size(tRS_sD, mode=[3])
cute.copy(
tiled_copy_r2s, tRS_rD_out, tRS_sD[(None, None, None, epi_buffer)]
)
cute.arch.fence_proxy(
cute.arch.ProxyKind.async_shared,
space=cute.arch.SharedSpace.shared_cta,
)
# barrier for sync
cute.arch.barrier()
# Get the global memory coordinate for the current epi tile.
epi_tile_layout = cute.make_layout(
epi_tile_shape, stride=(epi_tile_shape[1], 1)
)
gmem_coord = epi_tile_layout.get_hier_coord(epi_idx)
# Copy from shared memory to global memory
if warp_idx == 0:
cute.copy(
tma_atom_c,
bSG_sD[(None, epi_buffer)],
bSG_gD[(None, gmem_coord)],
)
cute.arch.cp_async_bulk_commit_group()
cute.arch.cp_async_bulk_wait_group(self.epi_stage - 1, read=True)
cute.arch.barrier()
return
Conclusion
I hope this blogpost gave a good overview of the Pipelining mechanism that is needed to archive peak performance on Tensor Cores. It furthermore should provide a solid understanding of why we need different phases in a CUTLASS algorithm.
If you want to get a different view on the Pipelining mechanism for the C++ API of CuTe you can check out the Colfax Blog.
I am curious to discuss ideas about MLSys in general and you can contact me via Linkedin.