Chunkwise Gated Delta Rule is important when performing operations such as prefilling or training with the recently popular Gated Delta Attention formulation.
In essence, in the chunkwise algorithm, we want to transform the naive recurrent equations for the transition from one timestep to the next into a form that is more GPU-friendly. This works by splitting the sequence length into chunks and then deriving formulas to perform the transition from one chunk to the next via matrix multiplication. For Gated Delta Net, this is not completely straightforward, which is why I will derive the transition formulas step by step in this blog post. For educational purposes, we start with Linear Attention, then move to the Delta Rule, and finally to the Gated Delta Rule.
Chunkwise Linear Attention
where denotes the i'th row relative to the beginning of the chunk (we start to count from 1) of the matrix and similar for . is simply and is this state shifted by timesteps.
For the output we have
Note we can write this in matrix form as
and
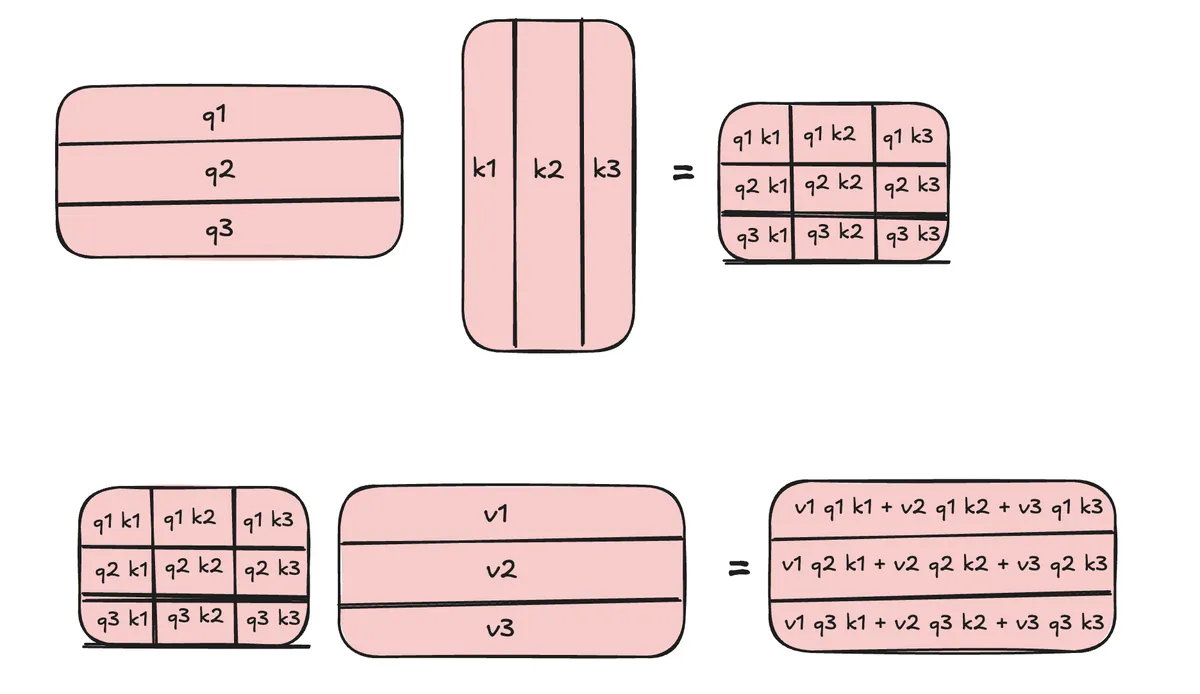
where is the causal mask. Why we need causal mask can be understood in a picture:
But we see that the sum at timestep relative to beginning of chunk should just contain summands. This is achieved by causal masking which will eliminate all upper right entries from the matrix above and thus gives us summands for th row in second matrix.
Chunkwise Delta Rule
For Delta Rule we have state update as
As above we can expand the state by applying recursion to obtain the equation for an offset from the start of a chunk:
We will prove useful identity for these terms now.
Let's prove that
By induction over .
:
choose and the equation is fulfilled.
:
For the induction step, we continue from
and use the induction hypothesis
Thus,
Expanding the product yields
Since is a scalar, the last term can be rewritten as
Therefore,
Now define
Then we obtain
This is exactly the desired form, so the induction step is proved.
Moreover, the proof gives a recursive way to compute the vectors : start with
and for compute
Let's prove that
By induction over .
:
Choose and the equation is fulfilled.
:
Let's use the following identities to bring this into a form where we can use the induction hypothesis:
Split up such that we first expand the last sum, and then the last product term for each product, and factor that out:
This gives us
Plug in the induction hypothesis:
Now distribute:
Since is a scalar, this becomes
Group the last two terms together:
Factor out :
Define
Then we obtain
which is exactly the desired form.
Moreover, the proof gives a recursive way to compute the vectors : start with
and for compute
Hence, for every , we can write
Simple vectorised expression
We have now an elegant form for translation of timesteps for chunk within this chunk:
where the terms on the right side were derived above.
Matrix equation
We can rewrite for the transition from one chunk to the next in a matrix notation:
Note that can be understood by writing
The matrix multiplication will that give us
Which corresponds to the transition from one chunk to the next we'd obtain from the vectorised formulation.
In similar way we can write
Let's derive closed forms for and .
Write
and
Also define
and
The entries of are
Now define for a matrix as the matrix which keeps only the entries strictly below the main diagonal and sets all other entries to zero. In other words,
Using this, define
Its entries are therefore
Recall the recurrence
Since
the -th row of is
Similarly,
Therefore the recurrence is equivalent, row by row, to
Using the definition of , we can rewrite the sum as
Hence
Therefore
for every . Thus
Therefore
Substituting the definition of , we obtain
Now define
Then
In the same way, define
and
Recall the recurrence
Since
the -th row of is
Similarly,
Therefore the recurrence is equivalent, row by row, to
Again using the definition of , we obtain
Hence
Therefore
for every . Thus
Therefore
Substituting the definition of , we obtain
Using , this can be written as
Hence we have the closed forms
Plugging this into the expressions above yields
and
Matrix State and Output Form
We have
We can expand the brackets and factor out to obtain
For the output
Compare the similarity to linear attention:
and
Where we see that conceptually
Gated Delta Net
Gated Delta Net has update rule for the state
As above, we expand the state by applying recursion to obtain the equation for an offset from the start of a chunk:
Thus,
Cumulative gates
Define the cumulative gate
and for
By convention, , and we have
Since the gate factors are scalars, we can factor them out of the product and obtain
The remaining product is exactly the Delta Rule term , so
Using the result from the Delta Rule section,
where
and for
Therefore
Let's prove that
by induction over .
:
Choose
and the equation is fulfilled.
:
We first derive a recurrence for :
Split off the last term:
Factor out the last product term:
Hence
Now plug in the induction hypothesis:
Distribute:
Since and is a scalar, this becomes
Group the last two terms together:
Define
Then we obtain
This is exactly the desired form, so the induction step is proved.
Moreover, the proof gives a recursive way to compute the vectors : start with
and for compute
Hence, for every , we can write
Simple vectorised expression
Substituting the expressions for and gives
Matrix equation
As in the Delta Rule section, define
and
The matrix is unchanged from the Delta Rule case, so
Now define
Also define the matrix by
To see how the recurrence for leads to a matrix equation, write the recurrence again:
As above, the -th row of is
and the -th row of is
Moreover,
Hence the recurrence is equivalent, row by row, to
Now define
Its entries are
Therefore
Thus
for every . Hence
Solving for gives
Matrix State and Output Form
Following the paper on Gated Delta Net, define the rescaled quantities
Let , , and be the row-wise matrix forms of these vectors. Then the hardware-efficient chunkwise state update is
For the output we obtain
Compare this with the DeltaNet equations
and
We see that Gated DeltaNet keeps the same chunkwise structure, but replaces the un-gated quantities by the gate-rescaled forms , , , , and the UT-transformed matrix .
When for all , we have , hence
and reduces to the strictly lower-triangular causal pattern, so the equations reduce to the DeltaNet chunkwise formulation.
Conclusion
I hope this blogpost could make the calculations involved in chunked wise formulation of the various variants of Linear Attention more accessible. Please check out the paper that introduces Gated Delta Net for more information on the Gated Delta Rule.
If you like to connect or exchange ideas you can reach me on Linkedin or X.