Applied introduction to Categorical treatment of CuTe
Introduction
Colfax recently released an excellent paper on the categorical foundations of CuTe. In a previous blog post, I calculated many of the examples from Chapter 2 by hand. In this blog post, I do the same for Chapter 3.
Chapter 3 gives readers a new approach to understanding CuTe Layouts by introducing categories and morphisms that operate on them. It shows how to encode these morphisms into the familiar CuTe Layouts, provides a new visual approach, and offers an alternative perspective on Layouts beyond the traditional treatment. In my opinion it is a very elegant approach that delivers a powerful method of calculations related to CuTe Layouts.
The reasoning behind each example may not be completely straightforward for newcomers, and I hope this small companion guide helps bridge that gap. I focus on building intuition through direct calculation, just as I did for Chapter 2.
For a complete and rigorous treatment, please refer to the original paper.
Learning Notes

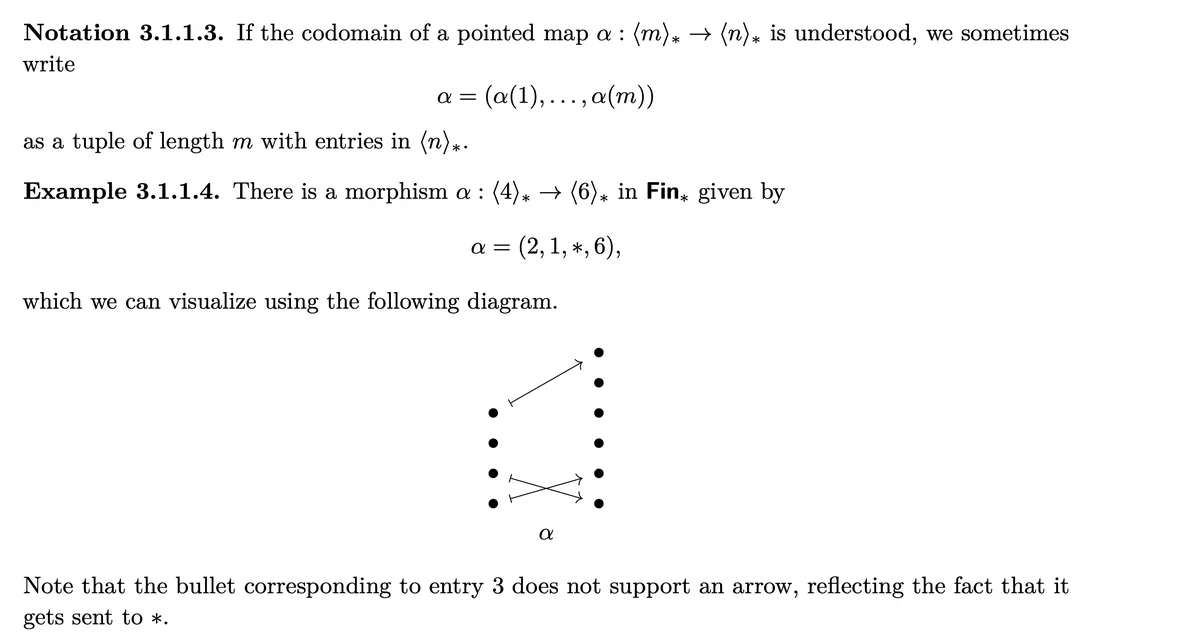
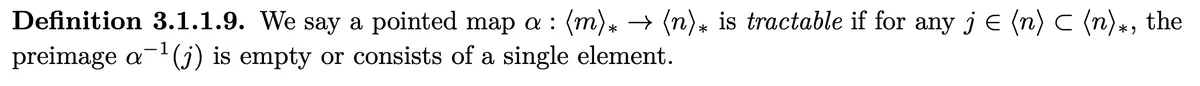
These could be also written down in the following fashion:

Examples:
and , than we can find an such that is a tuple morphism by seeing
- So .
and , than we can find an such that is a tuple morphism by seeing
- So or we could also choose . We see that we could call a "Wildcard" if we wanted to emphasise it's meaning.

For example is encoded by , , because , where we used that the empty product is . Note we could equivalently choose any number for .



Initially visit . Start with :
- , append Traverse to :
- , append
We have .
Therefore , and encode the Layout, as depicted in the picture.
Initially visit . Start with smallest stride, i.e. :
- , append . Continue with next stride :
- , append .
We have where the first entry corresponds to the second shape, i.e. we have and than encodes our Layout as depicted above.

Visually that means, that the upper entry has an arrow pointing to it. For all other entries it means that if an entry does not has an arrow to it than the entry is and the next entry will have an arrow to it.
Using this intuition the below is clear.
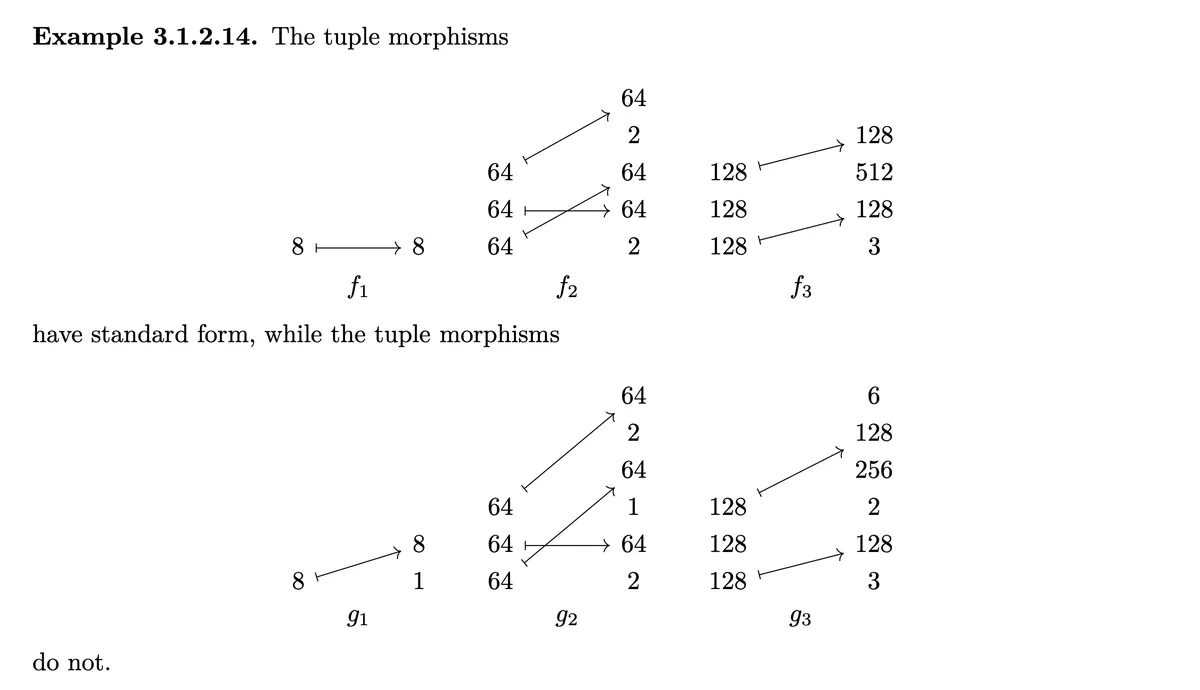
and are not in standard form because they have a one without an arrow to it. is not in standard form because after which doesn't have an arrow to it there comes which doesn't have an arrow to it.

Note this is necessary to avoid situations like
, where both as well as would encode .

That means given a non-degenerate tractable flat layout we can always find a unique encoding for this Layout!

Let's check opposite direction and apply our algorithm from above:
describes a cube layed out by column first for each plane and each plane is layed out after the previous one.
- , so we append .
- , so we append
- , so we append
Therefore we have and . This shows very clearly why we call this "identity morphism".
Let's take opposite, i.e. row major
- , so we append
- , so we append
- , so we append
This means we obtain and .
More generally an arbitrary row major Layout with Shape would give rise to and .

See below for the trivial construction of .
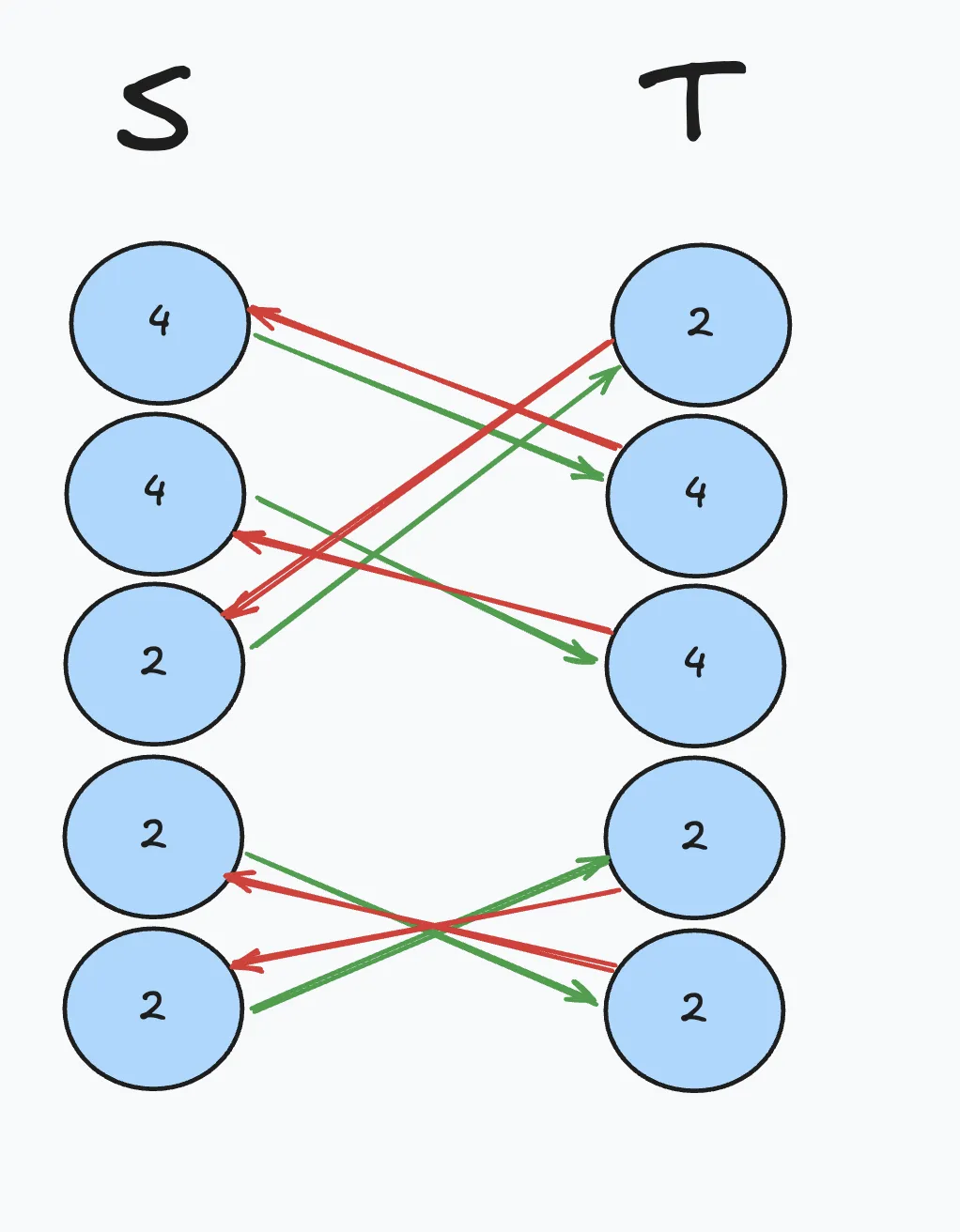
We have , with isomorphism leads to and the inverse which leads to .
Let us compose these Layouts in CuTe:
import cutlass.cute as cute
@cute.jit
def inverse():
L = cute.make_layout(shape=(2,2,2,4,4), stride=(2,1,64,4,16))
L_ = cute.make_layout(shape=(2,2,4,4,2), stride=(2,1,8,32,4))
I = cute.composition(L, L_)
cute.printf(L)
cute.printf(L_)
cute.printf(I)
if __name__ == "__main__":
inverse()
This will output
(2,2,2,4,4):(2,1,64,4,16)
(2,2,4,4,2):(2,1,8,32,4)
(2,2,4,4,2):(1,2,4,16,64) # Stride is (1, 2, 2*2, 2*2*4, 2*2*4*4) = (1,2,4,16,64)
We calculate this corresponds to , which corresponds to the column major Layout on . This is exactly what we get in CuTe.
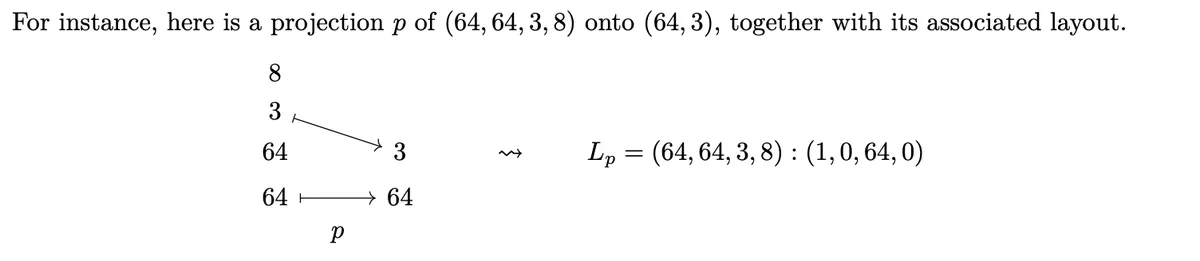
This is called a projection: , and . More general we call a projection if we take some indices and all of these indices have a counterpart where the value in agrees with the value in . maps these values and all other values get send to , i.e. the corresponding Layout mode has a stride of .
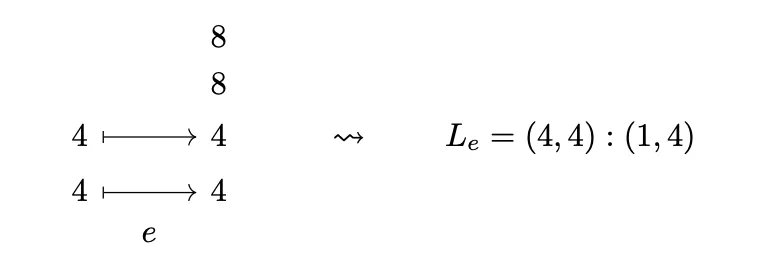
This is an expansion. We call an expansion a morphism from to with .
They will have Layouts , i.e. be column major. Note that composition will not do anything, because they are the identity if restricted to their domain in the codomain. Visually this should be also clear because if something "flows in" from the left into the expansion it will just flow in a straight line to the projection domain.


Recall

Lets apply that to the isomorphism over .
We have that and therefore . From here , , , . The associated Layout is and agrees with .
We can understand the "sandwiching" of by such that we use it to project into higher dimensional space via the inverse, perform our calculation there and project back.
We can therefore calculate the Layout function for arbitrary Layouts by identifying them with their morphism and using the above construction.

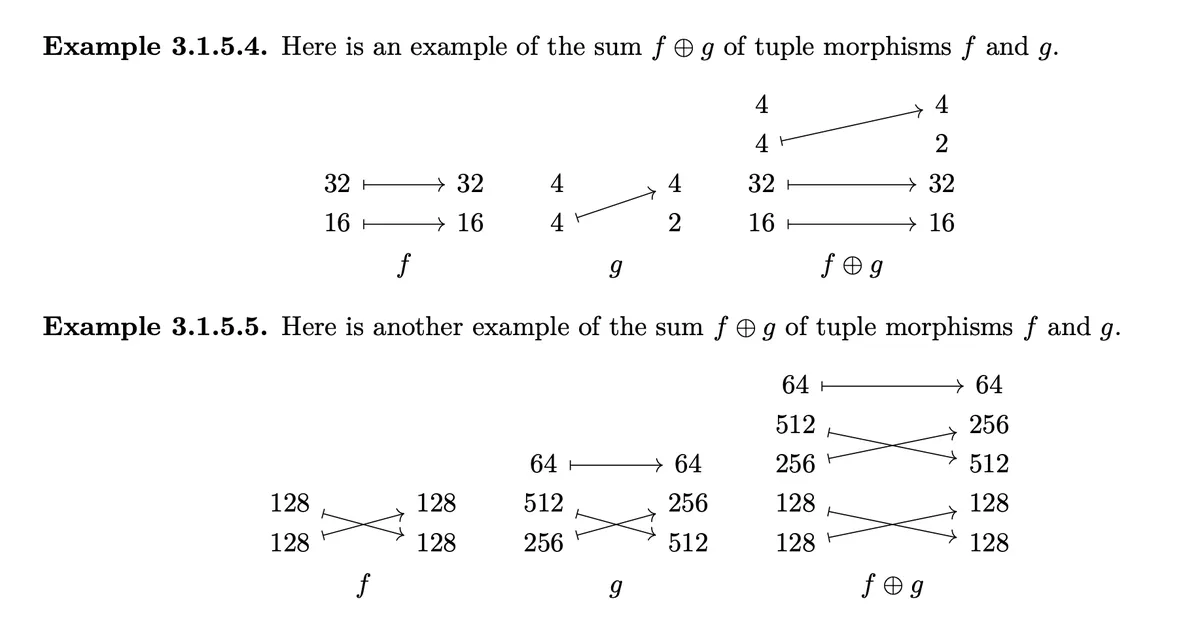
Note that the visuals correspond to the formula: Summing morphisms means extending them by "putting on top of ".
Let us quickly check how the associated Layouts are.
, . is the morphism , over and the associated Layout is . Note that we "extend" the layout into the additional dimensions while scaling the stride appropriately.

Squeezing a Layout just means to to remove redundant modes, i.e. ones with a mode of form . On morphisms squeezing will remove the ones from , restrict the morphism to the subset of non 1 indices and than factorise, i.e. absorb the ones not in the image of the morphism as described in 3.1.3.10.

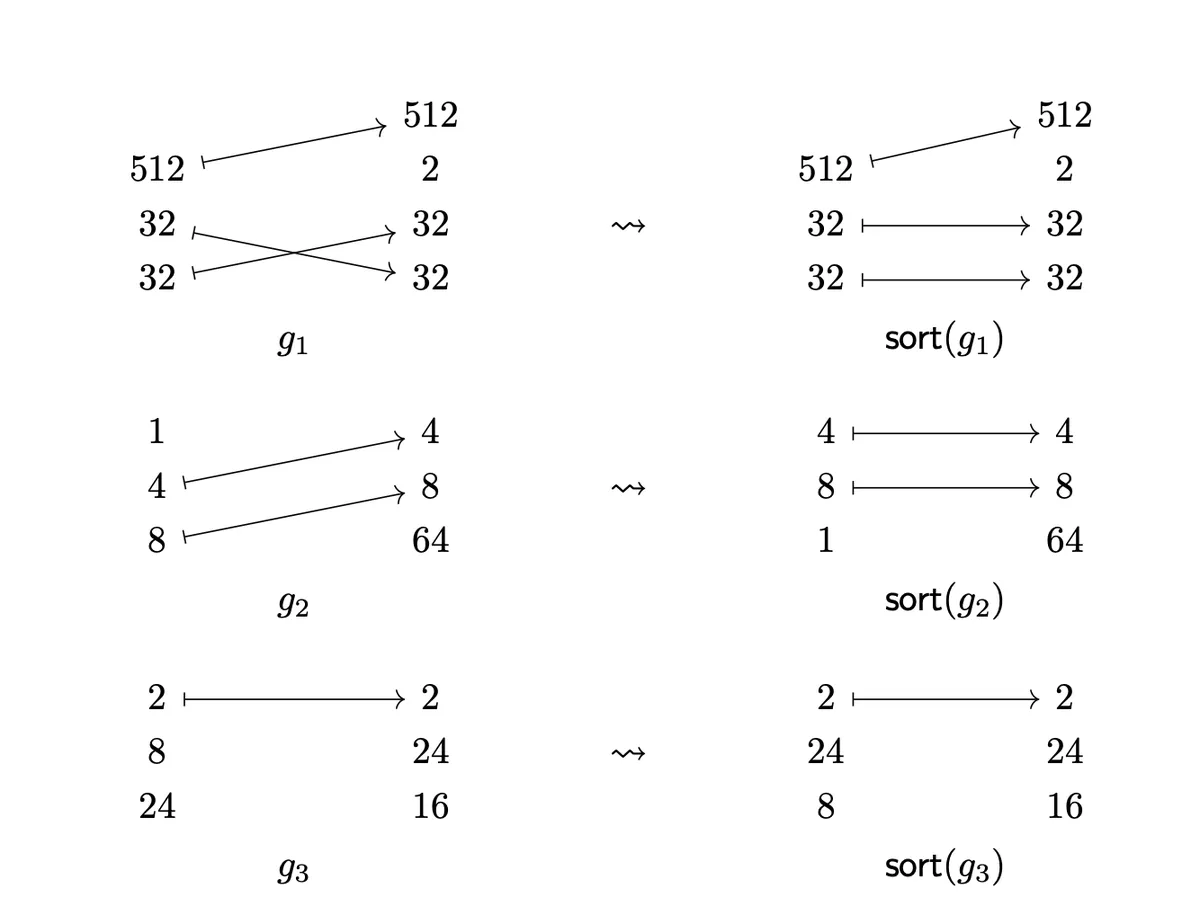
Remember that sorting a Layout will first sort the strides and than within the modes with equal strides by shape. Sorting the morphism means bringing a morphism into arrangement that fulfils above three conditions:
- If doesn't have an arrow to the codomain we want it to be before each that has one.
- If they both don't have an arrow to the right side we order them by their value and
- We don't want any "crosses" between arrows.
- violates 3).
- violates 1)
- violates 2) In all cases the sorting operation resolves the issues. The Layout of the resulting will agree with the sorted Layout corresponding to . Note that sorting a sorted morphism obviously leaves the morphism invariant.

Let us summarise the 4 conditions in 2) in words and give their visual interpretation
- If doesn't have an arrow to the right, has one
- If has an arrow to the right, than has doesn't have one.
- "points" to a higher point in than . (This implies the arrows cross)
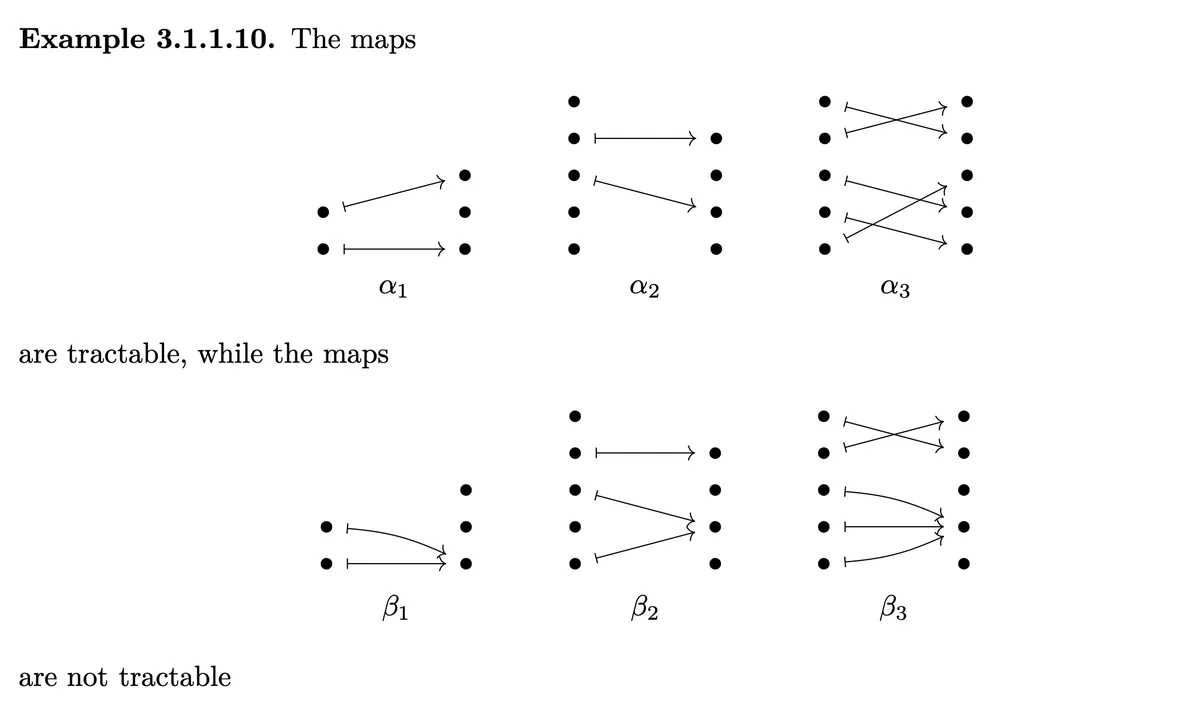
- "points" to a higher point in than . (This implies the arrows don't cross) Furthermore we have a value larger than one between the two values the two arrows point to. We demand S to be squeezed (i.e. all ones removed) and for each entry except the last one one of the above 4 conditions to be true. Than we say a tuple morphism is coalesced.
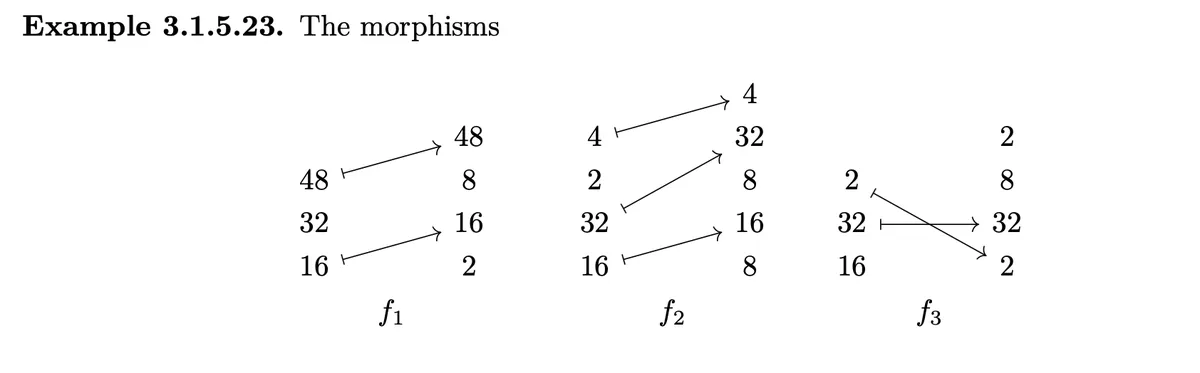
These are examples of coalesced morphisms. Obviously all are squeezed. To determine if the tuple morphisms are coalesced we need to check above four conditions for each entry except the last:
is coalesced because we have that has an arrow while doesn't have one. Furthermore has not an arrow while has one.
is coalesced because we have that condition 4) for and condition 2) for and condition 1) for .
is coalesced because we have condition 1) for and condition 3) for .
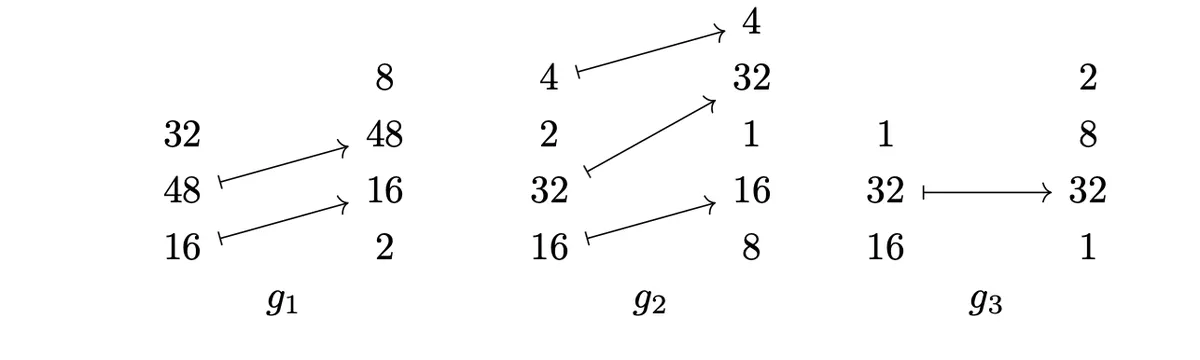
is not coalesced because we have for that points to a higher point and there is no value larger than 1 between them.
is not coalesced because points to a higher point than and there is only a 1 between them.
is not coalesced because is unsqueezed.
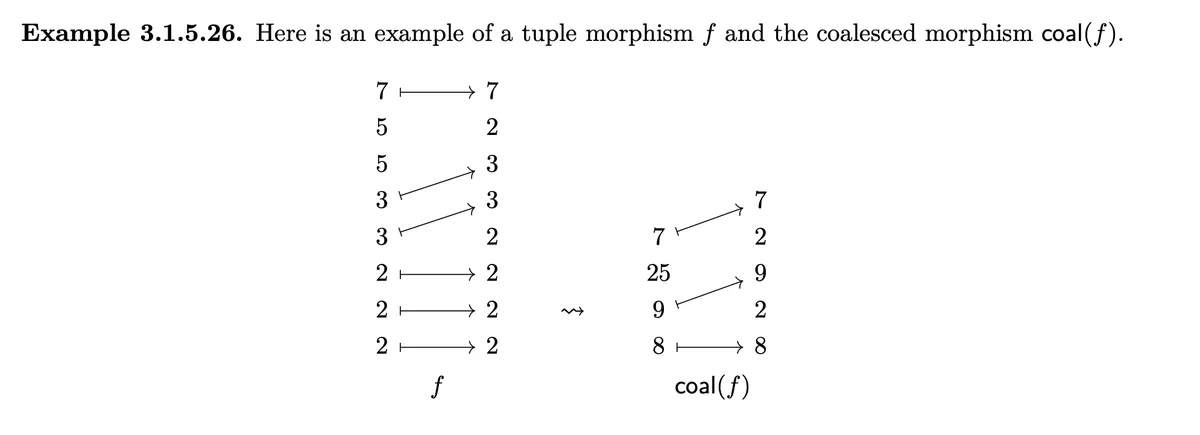
We coalesce as follows.
- The three 2s "down" violate 4). We multiply them together on left and right and replace the three arrows by one.
- The same is done for the two threes above.
- The two fives violate the condition that on a value without arrow there should follow one with arrow, we multiply them together.

We coalesce as follows:
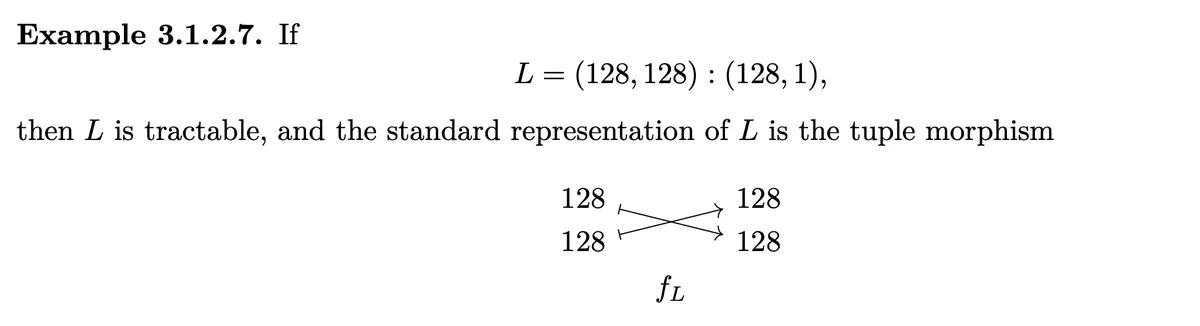
- We first squeeze , i.e. remove all ones from it
- Than 128 and 256 have both an arrow and the mapped values are not separated by value larger than 1. We reduce this by multiplying the corresponding values left and right.
Let's connect it to traditional Layout operation
- Than we perform coalesce, i.e. if than we replace it by .
- We see that so we reduce . Note that this is precisely the encoding of the morphism above!

Let lie over . We see . We see that is disjoint with but not with . Also is not disjoint with .
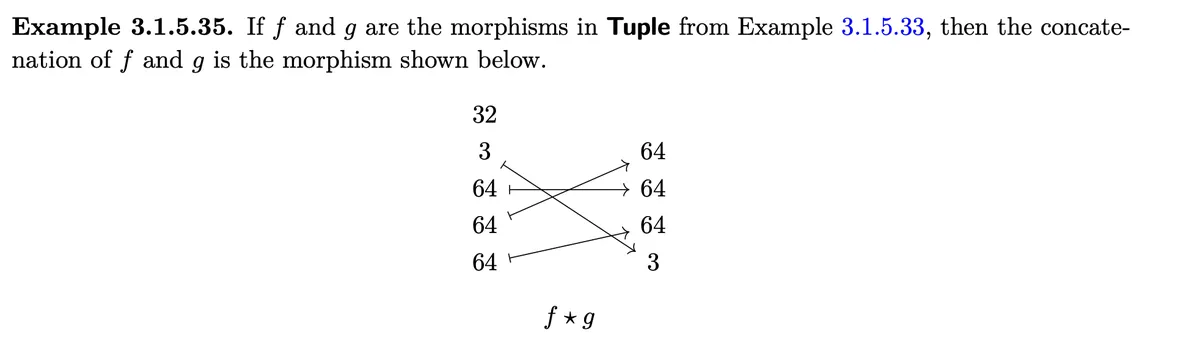
This is the concatenation of the two morphisms. Obviously its tractable, because the images are disjoint (as we see visually as well).

If two morphisms have disjoint image and the concatenation of the two leads to an isomorphism than we say that is complement of . Note for the above picture that is the case because the concat is obviously bijective and we can therefore construct an inverse to it as done above.
The Layouts associated to and are and , furthermore we have .
Let's calculate the complement to .
Note that up to sorting that agrees with from above which is a complement of . Note that this is given in 3.1.5.48.

Let's understand above example:
with . So we have . So we have that is defined from to over . This is also what we can see in the picture.

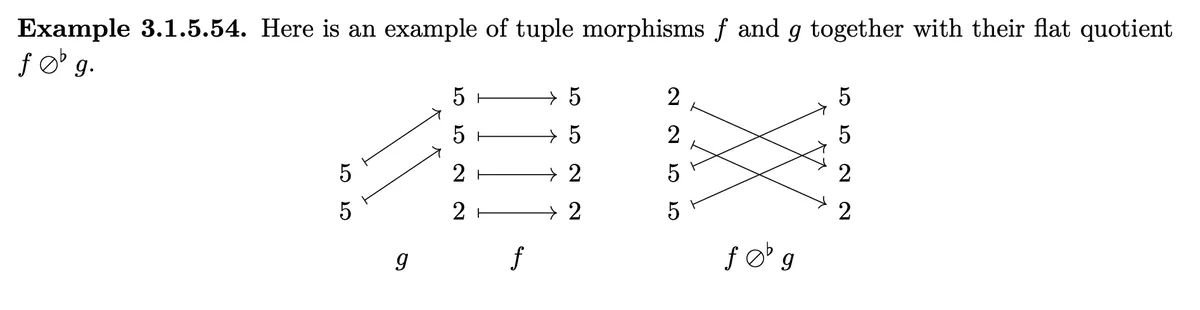
, .
- over
- Composed with this will not change because is the identity.

Here we have over and over . Also we have over . Let us use that to calculate the flat product. Let us do it visually.
This picture visualises

If we than perform coalesce with we will obtain the picture shown in above figure.

Lets understand the examples:
- , , , , .
- , , , , .
- , , , , .


Let us derive by hand:
over :
- (empty Product)
- Equip with gives
- Combining with gives
over
- , empty product
- because
- Equip with gives
- Combining with gives
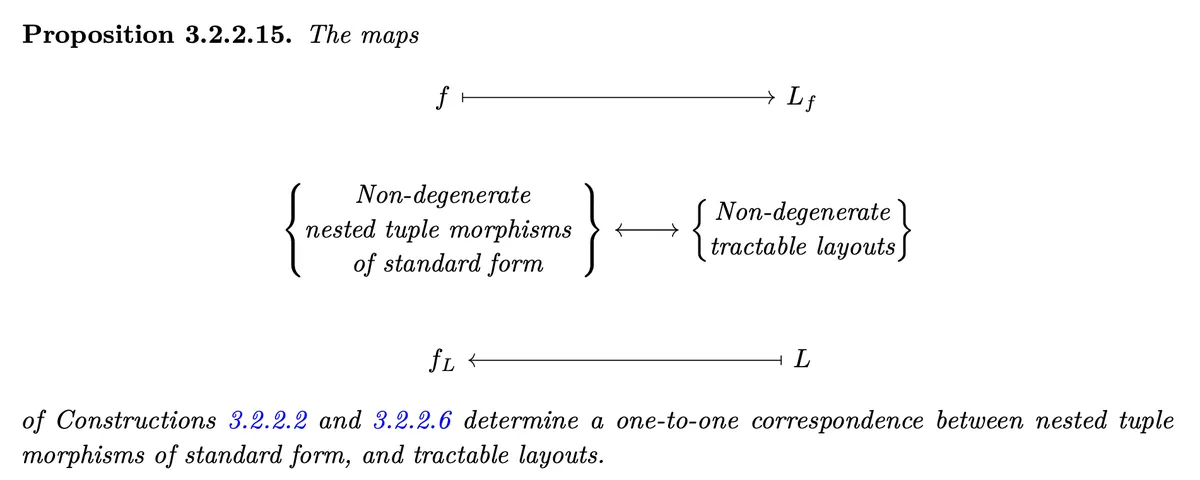
Definition of standard form is similar to above, see 3.2.2.10.

Note that concatenation works such that we define two nested tuples to be in concatenation if the corresponding flattening of nested tuples is in concatenation.
We may note that above we have very clearly for over and over that their concatenation is simply over . Than using that concat is map from as given in 3.2.6.4 will tell us with which profile, i.e. , to equip the above flat Layout and we obtain above result. Note that and .

Let us calculate above example.
We have that , so .
- over .
Before we continue let's remember:
Let us summarise the 4 conditions in 2) in words and give their visual interpretation
- If doesn't have an arrow to the right, has one
- If has an arrow to the right, than has doesn't have one.
- "points" to a higher point in than . (This implies the arrows cross)
- "points" to a higher point in than . (This implies the arrows don't cross) Furthermore we have a value larger than one between the two values the two arrows point to. We demand S to be squeezed (i.e. all ones removed) and for each entry except the last one one of the above 4 conditions to be true. Than we say a tuple morphism is coalesced.
Let us draw picture of .

Note that if we reduce the adjacent nodes into one by multiplying (because they violate 4) from above) we will obtain the following picture

Check for the first entry that it obeys rule 3) from above. Check for second entry that it obeys 3) as well. Therefore the morphism is coalesced. It is given by over .

Let us verify:
- over . Similar to calculation for complement above we have and therefore over .
- We perform "unflattening" by equipping with appropriate profile and obtain like shown above.

We have obviously that the is . We have that over . Therefore over . We than compose with and this gives . Lets determine by simply substituting the possible values.
- Therefore we have that over is the logical product as indicated in the picture.
Conclusion
I hope this paper makes the new calculation mechanism by Colfax more accessible. Please refer to their original Paper and consider starring the accompanying repo on Github. I am happy to connect on Linkedin to exchange ideas.